E-commercepaginering, SEO en canonieke URL’s bij Google: Een experiment
Een experiment: ik ben op zoek gegaan naar alternatieve manieren om paginering aan te bieden aan de Google-index op een SEO-vriendelijke manier, zonder dat dit zorgt voor dekkingsfouten of onlogische SERP’s op diepergelegen pagina’s.
Je kent het wel: je begint een webshop en voor je het weet biedt je 100.000 producten aan verdeeld over vele categorieën. Uiteraard allemaal op een template dat SEO-technisch goed werkt en ook nog eens gebruiksvriendelijk is. Dus zowel je CRO als je SEO is op stoom en je verkoop loopt goed. Het enige dat je maar niet opgelost krijgt is hoeveel producten je op een pagina plaatst.
Je SEO-specialist geeft je nog steeds het advies om de producten te verdelen over meerdere segmenten of pagina’s om de lading niet te hoog te maken en/of om het overzicht te bewaren. Ook hoor je in negen van de tien gevallen nog steeds dat je de “rel=nex rel=prev”-opzet moet gebruiken met een self-referencing canonical op de gepagineerde elementen (oftewel: domein.com/abcdef…?p=2, domain.com/abcdef…?p=3 etc.). Want dat moet volgens Google. Jammer. En het is een signaal eens rond te kijken naar een nieuwe SEO-specialist, want deze ideeën zijn al deels achterhaald.
Paginering voor Google
Paginering is een onderdeel van SEO dat altijd voor veel discussie heeft gezorgd. Wat is nou de beste manier van paginering waarbij je ook de producten op de diepergelegen pagina’s via een goede interne linkstructuur aan de zoekmachine aanbiedt? Want als je parameters uitsluit van indexatie, dan wordt het lastig voor de zoekmachines om de producten te vinden die je na pagina 1 online hebt staan. Je kunt dit oplossen met tekstlinkjes, sitemapjes, een “view all”-page en nog wat manieren. Maar wat is nou de beste?
Googles Guidelines: Altijd het antwoord
Dat zou je denken, maar helaas is dat dus niet meer het geval. Google gaf je vroeger drie opties voor paginering:
- Laat alles met een canonical verwijzen naar een “view all”-pagina.
- Gebruik de “rel=next/prev”-methode om je diepergelegen pagina’s naar elkaar te laten verwijzen
- Doe niets: we begrijpen best hoe websites in elkaar zitten.
Het advies over paginering is al een tijdje offline gehaald nadat Google’s John Mueller toegaf dat ze eigenlijk al heel lang niet naar die signalen kijken. Ik denk nog wel eens na over hoeveel budget en middelen er verloren zijn gegaan omdat SEO-specialisten dit per se geïmplementeerd wilden hebben “want het moet van Google”.
Het huidige antwoord van Google wijkt niet heel erg af van eerdere adviezen, waarbij we nog steeds dezelfde issue ervaren: genegeerde canonicals. Lees verder na deze vernieuwde handleiding van Google:
Selecting the best UX pattern for your site
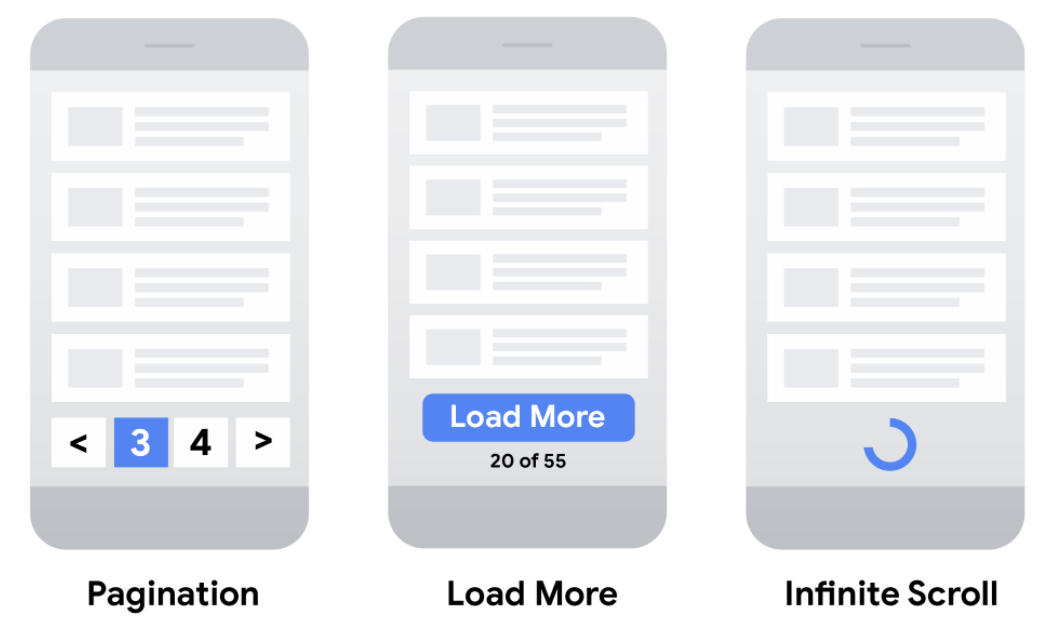
To display a subset of a larger list, you can choose between different UX patterns:
- Pagination: Where a user can use links such as “next”, “previous”, and page numbers to navigate between pages that display one page of results at a time.
- Load more: Buttons that a user can click to extend an initial set of displayed results.
- Infinite scroll: Where a user can scroll to the end of the page to cause more content to be loaded.
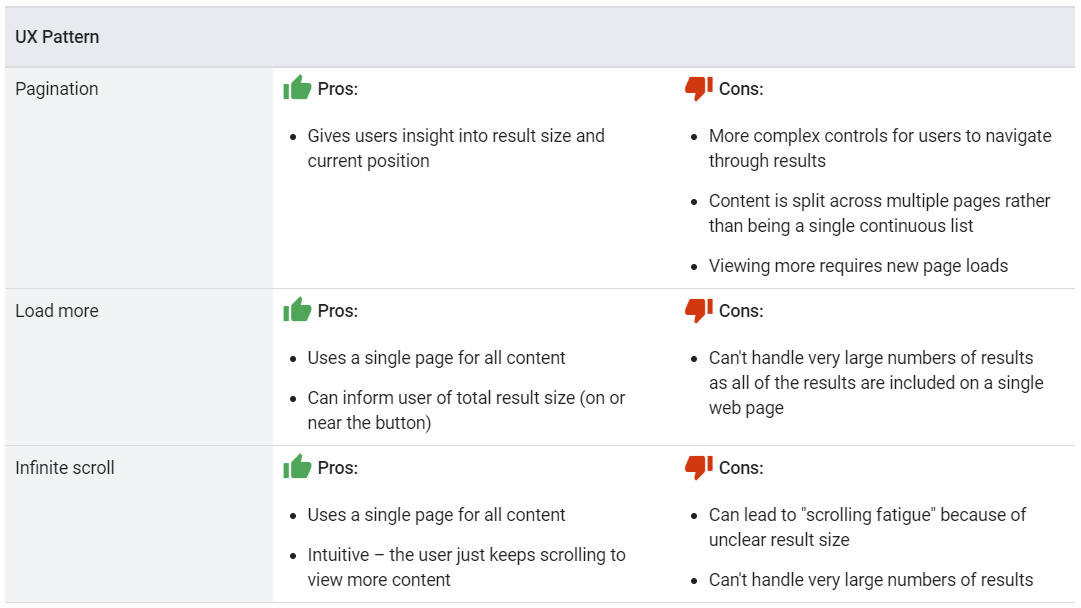
How Google indexes the different strategies
Once you’ve selected the most appropriate UX strategy for your site, make sure the Google crawler can find all of your content.
For example, you can implement pagination using links to new pages, or using JavaScript to update the current page. Load more and infinite scroll are generally implemented using JavaScript. When crawling a site to find pages to index, Google only follows page links marked up in HTML with <a href> tags. The Google crawler doesn’t follow buttons (unless marked up with <a href>) and doesn’t trigger JavaScript to update the current page contents.
If your site uses JavaScript, follow these JavaScript SEO best practices. In addition to best practices, such as making sure links on your site are crawlable, consider using a sitemap file or a Google Merchant Center feed to help Google find all of the products on your site.
Google denkt het beter te weten
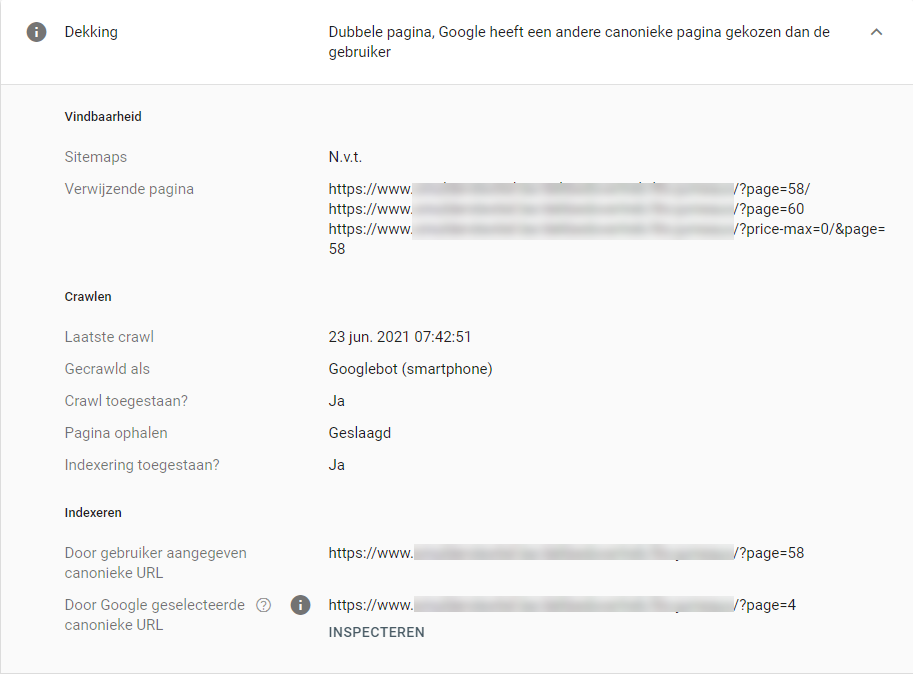
Buiten het feit dat Google er niet naar kijkt lijken canonicals op zich een prima oplossing. Ware het niet dat Google in bepaalde gevallen zelf niet weet wat ze met de canonieke link willen (of, als ze het wel weten, houden ze dat voor zichzelf). Bovendien schijnt niemand zich te realiseren dat een canonieke annotatie alleen geldt voor identieke pagina’s op een afwijkende URL, of bij templates met een productschema waarbij slechts een element – zoals bijvoorbeeld een kleur – afwijkt (configureerbaar/simpel). Google laat je soms denken dat je de canonical goed gebruikt, maar het dekkingsrapport geeft het echte antwoord.
Google heeft namelijk een tool die je laat zien waar je dekkingsfouten zitten, en mensen die van klikken houden hebben vast al eens gezien dat daar ook de regel staat: “Dubbele pagina, Google heeft een andere canonieke pagina gekozen dan de gebruiker”. Oftewel: “Hey webmaster, Bekijk het maar! Ik bepaal zelf wel wat ik doe!”. En ja hoor, de ene na de andere canonieke URL wordt genegeerd. Je kunt iets suggereren, maar een harde wet is dat voor Google niet.
Het probleem: volgzaamheid
Wat willen we:
- We willen paginering op een juiste manier laten indexeren zodat onze diepergelegen producten ook gemakkelijk geïndexeerd kunnen worden.
- We willen ook dat Google deze pagina’s niet aanmerkt als duplicate content.
- We willen niet dat deze pagina’s boven de ‘hoofd’-pagina worden vertoond in de SERP.
Wat krijgen we:
- Google negeert canonicals op paginering.
- Google merkt pagina’s aan als duplicate content.
- Google laat soms dieper gelegen pagina’s eerder zien dan de root-pages.
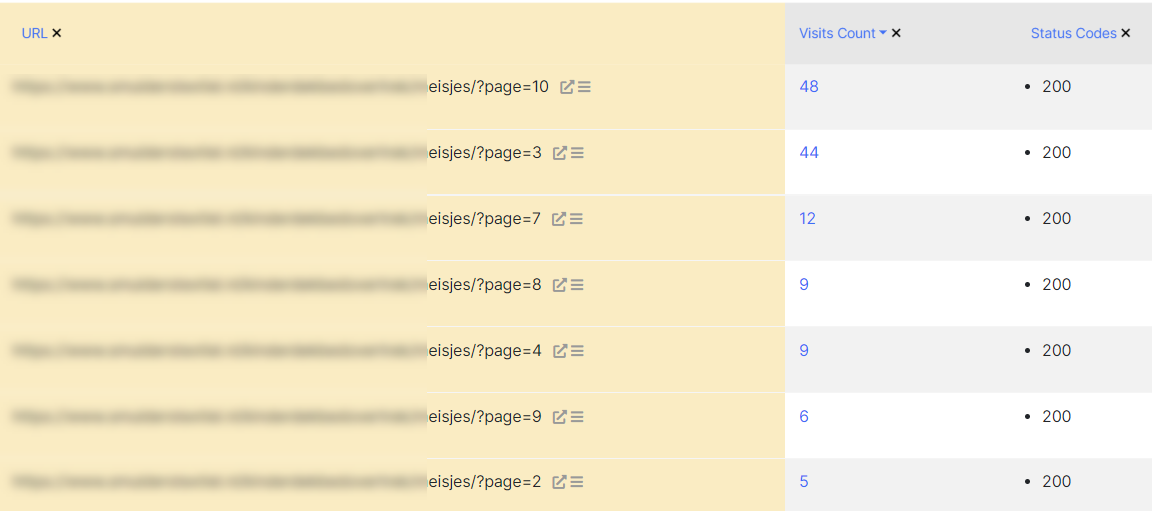
- Scheefgroei die we op ‘correcte’ paginering uit de serverlogs krijgen. De Googlebot roept dieper gelegen “?p=”-pagina’s soms vaker aan dan degene die het dichtst bij de bron van de paginering zijn.
Als je doet wat je altijd deed, dan krijg je wat je altijd kreeg. De oude situaties werken dus niet meer. Canonicals gaan we enkel nog zelfverwijzend op non-parameter-pagina’s hanteren en de rest blokkeren we middels meta-robots noindex/nofollow (behalve de paginering, en SID’s en Clid’s, waar het nu niet om gaat).
Helaas gaat dit nog veel te vaak mis: een gemiste kans. We moeten als SEO-specialisten juist geen makke lammetjes zijn. Cloaking is niet okay, maar er leiden altijd meerdere wegen naar Rome. Op zoek dus naar een andere insteek.
Experiment
Een gepagineerde pagina is een subpagina of onderdeel van het geheel aan informatie dat je op de root-pagina aanbiedt. Dus uiteindelijk zou je pagina’s als een minisilo van het topic kunnen zien: een mini interne structuur onder je categorie. Want laten we wel wezen, een pagina is een sectie en nooit een root-topic.
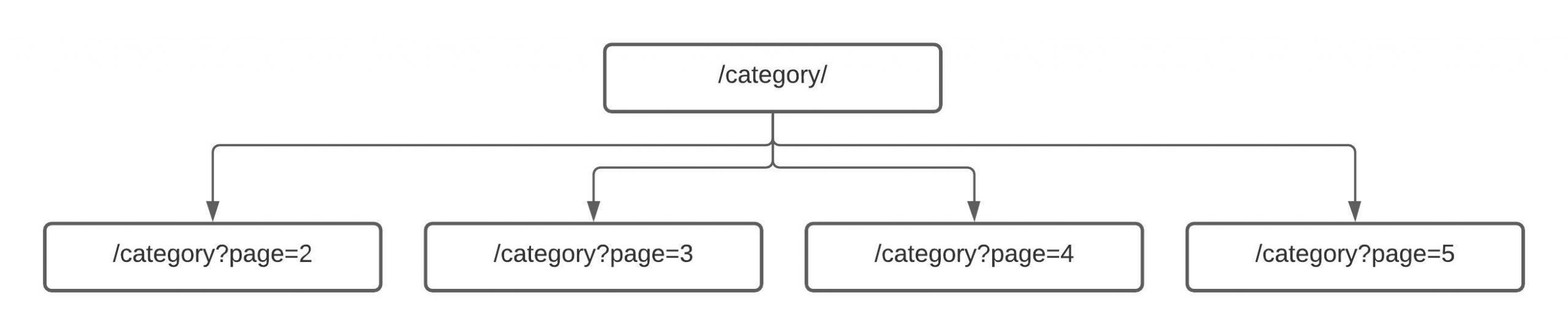
Waarom behandelen we deze pagina’s dan niet hetzelfde als een reguliere hiërarchische structuur? Ik was op zoek naar een oplossing en wilde dit eerst op kleine schaal testen bij een een van mijn e-commerceklanten. Daarom bedacht ik dat als we de pagina’s gewoon opmaken als subsecties van de root-categorie, dat Google ze dan wellicht beter als secundair zou beschouwen, zonder dat we last van dekkingsfouten of inconsistente SERP-vertoningen hebben.
We hebben onderstaande zaken uitgevoerd op alles wat “?p=*” was:
- Canonical van de pagina.
- “Rel=next/prev” van de pagina’s.
- “Allow ?p=*” in de robots.
- Meta robots index-follow in de head.
- Dynamische page title waar voor de URL insertion eerst “pagina *” wordt ingevoegd.
- Dynamische description waar eveneens “pagina *” wordt ingezet bij een “?P-*”-parameter.
- Kruimelpad extended naar “home > cat > pagina*”.
- Ook de JsonLD breadcrumbs hebben deze extensie gekregen.
- De <h1> kreeg ook een “pagina *”-suffix.
- Uitgebreide (SEO-)teksten onderaan het productaanbod verwijderd bij een “p=*”-URL.
- Een separate “sitemap.xml” aangemaakt voor alle gepagineerde pagina’s (met een lagere prioriteit: baat het niet dan schaadt het niet).
Eigenlijk is dit allemaal best simpel, maar ik heb het nog niet eerder gezien, dus ik was benieuwd wat dit zou doen met de dekkingsfouten en de weergaves in de SERP.
Experiment: Eerste versie positief
Na implementatie zagen we in eerste instantie niet direct resultaat. Wat opviel was dat er in ieder geval geen dekkingsfouten bij kwamen, maar dat de oude dekkingsfouten bleven staan. We hebben een paar van die oude gevallen handmatig opnieuw aangeboden aan de zoekmachine, maar ze werden niet meer geïndexeerd of verkeerd toegewezen.
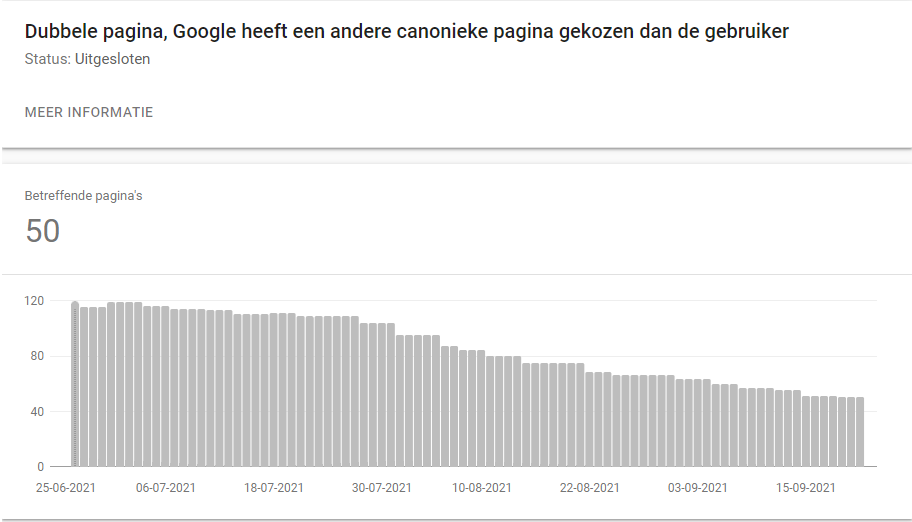
We hebben het experiment op 25 juni live gezet. Na 23 juni zijn er geen fouten meer bij gekomen en werden uiteindelijk alle oude dekkingsfouten stuk voor stuk opgeschoond. De set lijkt niet groot maar als je een e-commercewinkel met self-referencing canonicals op paginering, bekijk het dekkingsrapport eens (iets met een uptrends op genegeerde of anders toegewezen canonicals op paginering).
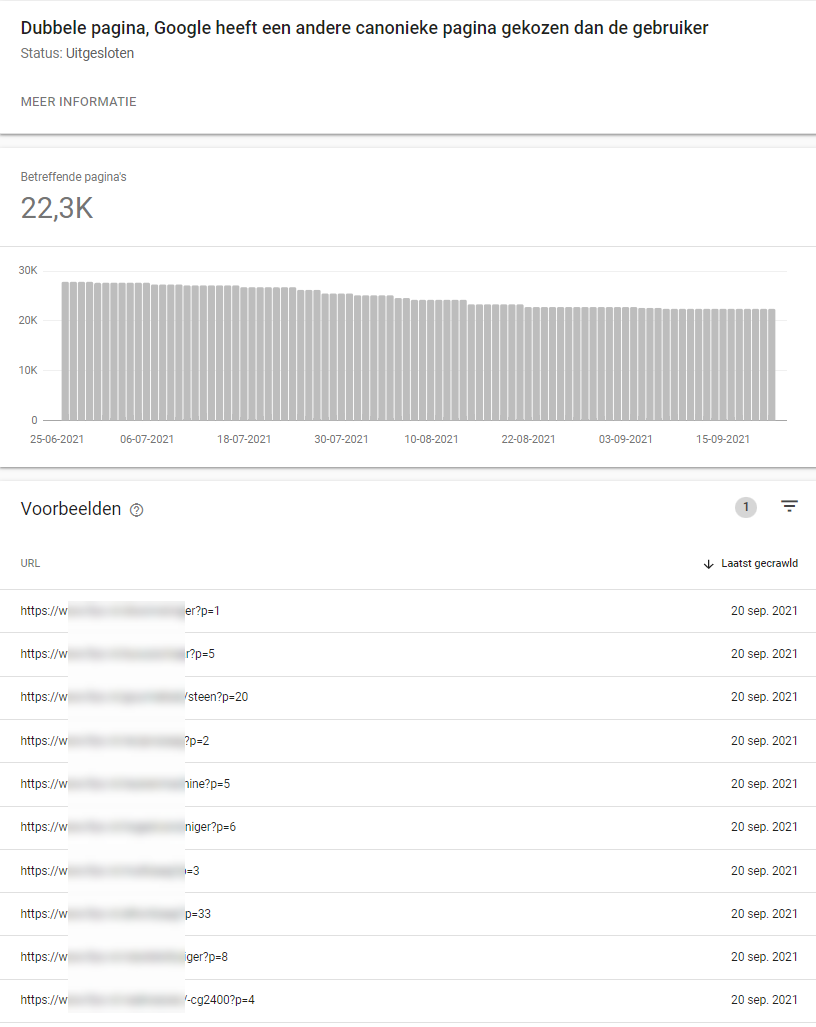
Nu dit eerste experiment redelijk succesvol lijkt gaan we dit ook inzetten bij een account waar we niet 128 genegeerde canonicals hebben,maar meer dan 22.000. Er zijn echter meer keuzes te maken op het gebied van paginering, dus de kans op meerdere experimenten is zeker aanwezig. Wordt vervolgd!
Over de auteur: Gerk Mulder is Senior SEO Consultant bij Briljante Geesten.
Op de hoogte blijven van het laatste nieuws binnen je vakgebied? Volg Emerce dan ook op social: LinkedIn, Twitter en Facebook.
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond