Waarom ziet de ‘Fetch als Google’ er anders uit dan de website in de browser?
Als goede SEO’er of developer wil je uiteraard weten hoe Google de website eigenlijk echt ziet of zal gaan indexeren. Dit kun je doen door (de testversie van) de website in Google Search Console te ‘fetchen’. Maar wat nou als de fetch iets anders weergeeft dan wat je in de browser ziet?
Zie je bijvoorbeeld witte pagina’s, lege vlakken, pagina’s die maar half worden weergegeven of andere dingen waar je als SEO-er hoofdpijn van krijgt? Lees dan dit blog goed door, want hierin bespreken we vijf mogelijke oorzaken van dit probleem.
Website bouwen 101
Voordat we de diepte in duiken, een kort antwoord op de vraag ‘Hoe werkt het fetchen als Google nu precies?’ Weet je al hoe fetchen werkt, scroll dan verder.
- Wil je een bestaande website fetchen als Google? Ga dan gelijk naar stap 4. Is de website nog in ontwikkeling? Zorg dan voor een testomgeving van de website.
- Zorg ervoor dat deze testversie niet geïndexeerd kan worden. Een van de opties om dit te doen is een user agent: * disallow: / in de robots.txt te plaatsen.
- Verifieer de testwebsite in Search Console, via bijvoorbeeld de HTML tag of Google Tag Manager. Om dit voor elkaar te krijgen moet je de GoogleBot tijdelijk toestaan in de robots.txt. Dit doe je door de disalllow in allow te veranderen.
- Vervolgens fetch je de website als Google (crawlen > fetchen als Google > ophalen en weergeven).
- Vergeet niet om de robots.txt na de fetch zo snel mogelijk weer op disallow te zetten als het om een testomgeving gaat.
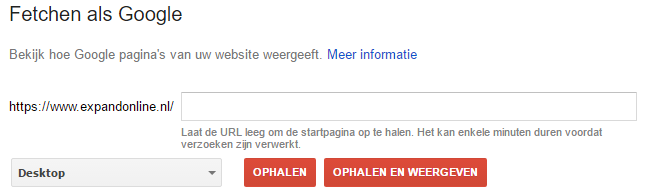
Afbeelding 1: Fetchen als Google voor dummies
Is GoogleBot slechtziend?
Met de fetch krijg je een goede indicatie van wat Google daadwerkelijk ziet op een pagina. In ons voorbeeld hieronder (slechts een van de mogelijke weergaven) is er sprake van dat er na de header en de eerste <section> (content blok) geen andere content meer wordt weergegeven. Met andere woorden, één groot wit vlak. Dit staat niet alleen bij ‘Dit is hoe GoogleBot de pagina heeft gezien’, maar ook bij ‘Dit is hoe een bezoeker op uw website de pagina zou hebben gezien’.
Een ware hel voor SEO als je wél content op je website hebt staan, maar Google deze niet ziet. Bij een test in de browser (zowel desktop als mobiel) is er niets aan de hand. Maar hoe dan? Wat sloopt de GoogleBot?
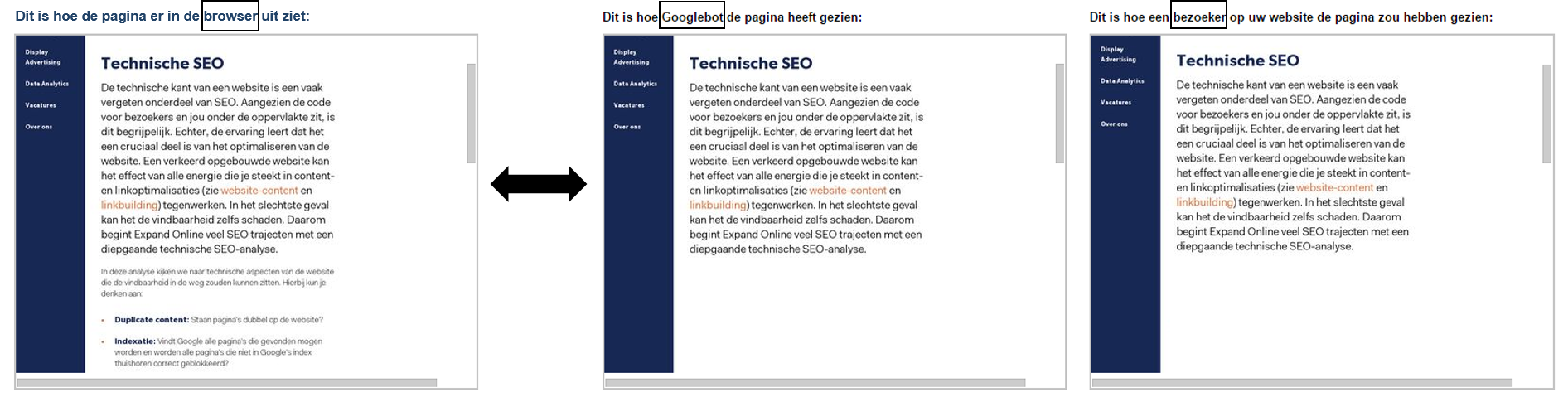
Afbeelding 2: Voorbeeld van hoe Google Fetch verkeerd kan gaan (v.l.n.r. Browser, googlebot, browser volgens googlebot)
Oorzaken: The vier ‘Usual Suspects and an odd one’
Hoe kom je er achter wat er aan de hand is als Fetchen als Google iets anders weergeeft? Bijvoorbeeld als je een bijna eindeloos scrollbare witte pagina ziet? Dit zijn de vier meest voor de hand liggende oorzaken met de vragen die je jezelf moet stellen en één vreemde eend in de bijt.
- Resources blocked in Robots.txt
Mag Google overal bij of zijn er dingen geblokkeerd? Check in de robots.txt of er een disallow aanwezig is op CSS, JS, Fonts, images, etcetera die Google verbiedt om die bestanden op te halen (en dus weer te geven). Ondanks dat dit een open deur is, is dit wel een veel voorkomende fout. Let op; in zo’n geval zie je waarschijnlijk ook een verschil tussen ‘Dit is hoe GoogleBot de pagina heeft gezien’ en ‘Dit is hoe een bezoeker op uw website de pagina zou hebben gezien’.
- JavaScript Frameworks
Wordt er gebruik gemaakt van een JavaScript Framework (AngularJS, Meteor, Backbone.js, etc.)? Wordt de pagina server- of clientside gerenderd? Ziet Google wel alle HTML? Indien dit de oorzaak is, zie je vaak één grote witte pagina zonder content. Dus waarschijnlijk niet zoals in het voorbeeld (Afbeelding 2) een deel van pagina wel en ander deel niet.
Worden er wel JS Frameworks gebruikt en worden de pagina’s clientside gerenderd, dan kun je dit eenvoudig in je browser testen. Om er achter te komen of de site wel of niet clientside gerenderd wordt, onderneem dan de volgende twee stappen:
- Bekijk de bron van de pagina. Als er geen content in de bron staat is de kans groot dat er sprake is van clientside rendering.
- Zet je JavaScript uit, bijvoorbeeld met behulp van de Web Developer plug-in in Chrome, en bekijk hoe de pagina wordt weergegeven. Als al je content alsnog op de pagina staat, is dit niet de oorzaak van het probleem.

Afbeelding 3: Disable JavaScript met de Chrome Web Developer plug-in
- Asynchrone Technieken
Wordt er gebruik gemaakt van lazy loading? Is er een infinite scroll, parallax scrolling of wordt er iets anders met AJAX asynchroon geladen? Ook al geeft Google aan dat ze tegenwoordig JavaScript kunnen crawlen, you can never be too sure. Als Google JavaScript dus niet goed zou crawlen, zal je de elementen die je niet op de pagina te zien krijgt ook niet terugvinden in de broncode.
Controleer dit door de ‘Gedownloade HTTP-reactie’ van de fetch te bekijken en check of je de elementen die je op de pagina had verwacht te zien, terug kan vinden in deze code. Pro-tip: deze output is (ook tot onze grote ergernis) niet ‘normaal’ te kopiëren of doorzoeken.

Afbeelding 4: Gedownloade HTTP reactie van een Fetch in Google
- CSS die pas worden geactiveerd na het laden
In het verlengde van het crawlen van JS door Google, zie je nog wel eens dat de CSS wordt aangepast of geactiveerd na het laden van de pagina. Dit kan bijvoorbeeld zijn om de pagina responsive of adaptive weer te geven. Deze test kun je doen door de pagina op verschillende resoluties te bekijken.
In Chrome druk je op F12 en klik je het responsive icoontje aan om verschillende resoluties te bekijken. Het is echter vrij lastig om goed te interpreteren wat er gebeurt in je browser, check dus even met je webdeveloper.
Afbeelding 5: Developer Tools in Chrome
Violence is my last option
Ben je bij dit gedeelte van het blog aangekomen en heb je de oplossing nog steeds niet gevonden? Sta je op het punt een office meltdown te krijgen? Wacht dan nog heel even met het vakkundig ruïneren van je laptop.
- Googlebot is not human
Omdat GoogleBot zelf geen scherm heeft, is het vrij logisch dat ze geen vaste resolutie gebruikt bij het fetchen. Hierdoor is de viewport, het zichtbare gedeelte van de browser, in feite ‘eindeloos’. Uiteraard binnen de maximale limieten die Google heeft gesteld.
Daarbij is de viewport die Google gebruikt dus een approximatie van hoe de gebruiker de pagina op zijn scherm zou krijgen zonder te scrollen. Hierdoor kan het dus zo zijn dat de viewport anders wordt geïnterpreteerd door Google dan door je browser.
Zie je dus in je Fetch als Google dat de content ophoudt maar je wel nog een stuk naar beneden kan scrollen? En als je scrolt, zie je dan enkel je achtergrondkleur (bijvoorbeeld een wit vlak)? Dan kun je testen of de interpretatie van de viewport door Google mis gaat.
Stel in je Developer Tools een hoge viewport (1500 x 2500 pixels, responsive) in en kijk of je soortgelijk gedrag krijgt (zie afbeelding hieronder). Ook zal je zien dat als je de bron van de pagina bekijkt wel alle content aanwezig is.

Afbeelding 6: Developer Tools viewport instellingen
#Nerdalert
Voldoet jouw scenario aan bovenstaande dan is het zeer waarschijnlijk dat er gebruikt wordt gemaakt van de CSS eigenschap ‘viewport height’, specifiek dat deze is ingesteld op 100 procent.
De viewport height wordt vaak gebruikt in responsive design. Als er contentelementen op de pagina aanwezig zijn waarvan één van de CSS eigenschappen 100 procent van de viewport hoogte (100vh) is, zal Google deze elementen ‘oneindig’ lang maken.
Google ziet dus 100 procent van de viewport hoogte als eindeloos hoog en zal dus het eerste element wat het tegen komt met deze eigenschap uitvoeren en de overige elementen daarbuiten laten vallen. Dit zie je in de Fetch terug als een ‘leeg vlak’. Dit levert als resultaat op dat Google deze elementen niet zal weergeven als zichtbare (SEO) content op de pagina. Door het veranderen van 100vh naar min-height: 100 procent kun je het probleem oplossen.
Conclusie: niet alleen JavaScript sloopt de GoogleBot
Wanneer je ziet dat de fetch uit de Google Search Console een ander resultaat weergeeft dan dat je op basis van je browser verwacht, kunnen er dus meerdere oorzaken zijn. Niet alleen JavaScript is een mogelijk oorzaak van SEO-migraine, maar ook verkeerde CSS instellingen kunnen roet in het eten gooien.
Het lijkt er dus op dat Google nog niet is toegekomen aan de juiste interpretatie van het element (zoals dat is gedefinieerd door de W3C) in GoogleBot, maar dit wel al in Chrome heeft geïmplementeerd.
*) Bronnen voor dit artikel: De bevindingen in dit blog zijn gebaseerd op verschillende case studies uit de afgelopen 6 maanden
**) Dit artikel is geschreven in samenwerking met Mandy van Rossum
Deel dit bericht
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond
1 Reactie
Richard
check