Data-dienstverleners moeten hun kwaliteit meetbaar maken
Data-analyse is een jonge bedrijfstak met veel high-profile start-ups. Hun diensten draaien om het leren uit data en omdat dat bijna overal kan zijn de toepassingen breed. Ze varieren van partner-matching tot sports-analytics, het voorspellen van kredietkansen en risico-analyse. Een hoop publiciteit levert dat zeker op, maar hoe goed zijn deze jonge bedrijven eigenlijk? En hoe meet je dat?
Ik bedoel in dit geval dus de datadiensten waarbij de klant een kant-en-klaar eindprodukt krijgt en niet de leveranciers van software of adviseurs. De klant voert eigen gegevens in, waarmee de dienstverlener met een model een voorspelling of een oorzaken-analyse levert. Een kritische klant, die meer wil dan vage beloften, moet vooraf vier – helaas technische – vragen stellen:
- Wat is de kwaliteit van uw voorspellingen en verklaringen?
- Welke data zijn gebruikt?
- Welk type data-analyse is gebruikt?
- Welke variabelen in het gebruikte model zijn het belangrijkst?
Waarom?
1. Kwaliteit in data-analyse
Kwaliteit kan je op meer manieren benaderen; het is vaak een combinatie van objectief meetbare eigenschappen en resultaten en een subjectief gevoel over tevredenheid en bejegening. De te halen kwaliteitssnorm kan objectief zijn, maar vaak is deze individueel. In data-analyse is kwaliteit erg goed objectief meetbaar en ook de norm is objectief te bepalen.
Kwaliteit in data-analyse druk je uit in de nauwkeurigheid van de voorspelling of berekening van de oorzaken. De norm hiervoor is natuurlijk 100 procent nauwkeurigheid.
Kwaliteit is dan – afhankelijk van de aard van de voorspelling of oorzaak – goed te meten met indicatoren als:
- X% goed voorspeld, als het een klasse (bijvoorbeeld ‘gezond/ongezond’) betreft
- Model verklaart x% van data-variatie (R²), als het getallen (bijvoorbeeld ‘€250.000’) betreft
Het meten van de nauwkeurigheid van data-diensten heeft voor de gebruiker belangrijke voordelen:
- Vergelijken van dienstverleners
- Geven van kwaliteitsgaranties aan klanten wordt mogelijk
Nauwkeurige informatie ontbreekt
Vreemd genoeg vind je in alle publiciteit en op websites van dienstverleners geen informatie over de nauwkeurigheid van hun diensten. Vergeten of opzet? Het is opzet, want elk statistisch pakket (Excel, SPSS, R, Python, enz.) geeft automatisch de nauwkeurigheid van het berekende model. Anders dan vaak gedacht hoeft de toekomst hiervoor niet afgewacht te worden. Ook kwaliteitsgaranties over de nauwkeurigheid van de aangeboden diensten zul je niet snel aantreffen. En ook informatie, waarmee niet-gemiddelde klanten de waarde van de diensten voor hun specifieke geval kunnen beoordelen (denk aan een lelijke 55-plusser met een laag inkomen op een dating-site) is afwezig.
2. Welke data zijn gebruikt?
Data-dienstverleners berekenen een model met data, die dus een grote rol spelen in de kenmerken en de kwaliteit (=nauwkeurigheid) daarvan. De kwaliteit van de data bepaalt het model. Belangrijk is dat je inzicht krijgt of deze data ook jouw situatie omvatten. Ik denk vooral aan de periode waaruit de data stammen. Is deze recent genoeg? Het heeft bijvoorbeeld weinig zin om nu kredietkansen te beoordelen met een model gebaseerd op data van meer dan vijf jaar oud.
Een tweede data-eigenschap, die je moet kennen is de doelgroep waaruit de data verzameld zijn. Val jij daar binnen? Data over het bedrijfsleven in de VS bijvoorbeeld zijn ongeschikt om modellen voor Nederlandse bedrijven te berekenen.
3. Welk type data-analyse is gebruikt?
Er bestaan verschillende methoden om verbanden in data-bestanden te vinden. Ze zijn naast elkaar te gebruiken, maar de soorten data beperken de keuze. Je kiest de methode met de hoogste nauwkeurigheid. De bekendste is lineare regressie-analyse, waarbij een rechtlijnig verband tussen een oorzaak en het gevolg verondersteld wordt (*1). De nauwkeurigheid van het verband wordt gemeten met de R²; de mate waarin een model de variatie in het gevolg verklaart.
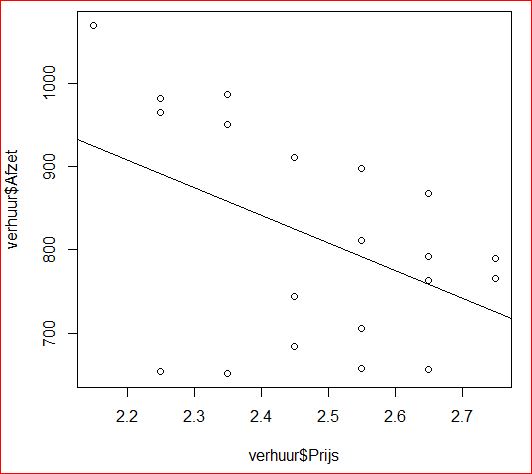
Lineaire regressielijn, die het verband weergeeft tussen een verhuurprijs (oorzaak) en het aantal verhuringen (gevolg). Vb.: Bij een prijs van € 2,75 mag je 740 verhuringen verwachten.
Een tweede methode, de beslisboom, is een visuele weergave van de verbanden in een bestand met de takken in een boom. Vanuit de top splitsten de takken zich. Elk tak splitst op de waarde van een belangrijke oorzaak en eindigt bij de waarde van een gevolg. Software berekent de optimale splitsingen. Te gebruiken data kunnen zowel klassen als getallen zijn. Vaak geeft een beslisboom-model een veel hogere nauwkeurigheid dan een lineair model uit dezelfde data.
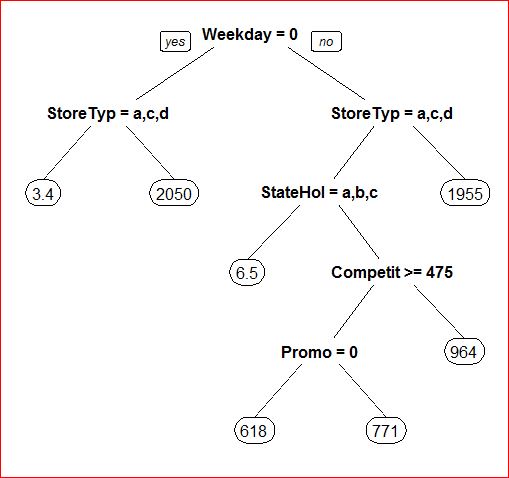
Beslisboom, die de dagelijkse omzet (x €10) van winkelfilialen verklaart en voorspelt. Die omzet wordt beinvloed door: wel/geen weekdag, winkeltype, wel/geen verplichte vrije dag, afstand tot concurrent en wel/geen lopende promotie. Vb.: Als het geen doordeweekse dag is en als het winkeltype niet A,C of D is, is de omzet €20.500
Een derde methode is Random Forests (‘Willekeurige beslisbomen’) waarin het programma naar willekeurige verbanden zoekt binnen een data-bestand (*3). Het kiest de combinatie met de hoogste nauwkeurigheid. Dat verband is vaak niet onder woorden te brengen en kan toevallig zijn, dus niet herhaalbaar.
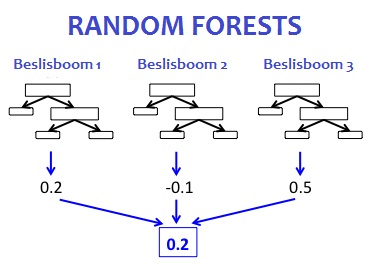
Vraag dus welke methoden uitgeprobeerd zijn op de data en welke de hoogste nauwkeurigheid had.
4. Wat bepaalt de uitkomsten vooral?
De oorzaken (variabelen) die een voorspelling of andere uitkomst bepalen zijn niet allemaal even belangrijk. Sommige hebben nauwelijks invloed, andere zijn juist doorslaggevend. Bijvoorbeeld bij het voorspellen van het aantal verhuurde fietsen bleken de weekdag en het uur doorslaggevend, maar was het weer juist onbelangrijk. Vraag naar het belang van oorzaken en beoordeel of ze je redelijk voorkomen.
Wees de ontwikkelingen voor
Data-analyse is een jonge bedrijfstak en het is verstandig als dienstverleners hun kwaliteit, dus hun nauwkeurigheid, zichtbaar maken. Je kunt de eisen van kritischer klanten afwachten, maar het versterkt de eigen concurrentie-positie als je uit eigen beweging informatie en garanties over nauwkeurigheid geeft. Bovendien worden data meer openbaar en bereikbaar voor nieuwe concurrenten. Aantoonbare nauwkeurigheid wordt dan een wapen in de groeiende data-concurrentie.
(*1) Meer informatie over lineaire regressie vind je hier.
(*2) Meer informatie over de beslisboom vind je hier.
(*3) Meer informatie over Random Forests vind je in dit filmpje.
Gerelateerde opleiding
Deel dit bericht
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond
1 Reactie
Ton de Jong
Interessant artikel dat terecht wijst op het belang om door te vragen bij data analyse naar de gebruikte methode, de nauwkeurigheid en de logische verbanden. In deze jonge bedrijfstak zit uiteraard ook (veel) kaf tussen het koren, maar koren met potentie is er ongetwijfeld ook!