Datagebruik bij de overheid: cruciale keuzes bij complexe besluiten
Van de overheid wordt terecht verwacht dat ze op een verantwoorde manier data inzet. Maar hoe bereik je dat doel? Begrip van het probleem is de helft van de oplossing. Keuzes zichtbaar maken is een belangrijke stap om tot verantwoorde datapraktijken bij de overheid te komen.
Met een serie artikelen levert Deloitte een inhoudelijke bijdrage aan het vraagstuk van verantwoord datagebruik bij de overheid. In het eerste deel is het dilemma globaal uiteengezet. In dit tweede deel gaan we dieper in op de cruciale beslismomenten in het beleidsproces en dataketens binnen de overheidsorganisatie. De analyse in deze blog vormt de basis om hierna mogelijke oplossingen te benoemen en daarna verder in te zoomen. Dat inzoomen doen we specifiek gericht op uitvoeringsorganisaties en gemeenten waar de datacomponent een grote uitdaging vormt. Deze serie maakt Deloitte in samenwerking met Kees Verhoeven, eigenaar van Bureau Digitale Zaken en voormalig Tweede Kamerlid.
Het unieke en complexe karakter van de overheid
De overheid heeft een unieke positie en een complexe organisatiestructuur. Diverse overheidsonderdelen en -niveaus zijn betrokken bij het maken van beleid, het uitvaardigen van wetten en toezien op naleving. Tussen Rijksoverheid, provincies en gemeenten en tal van organisaties en instanties die deel uitmaken van de overheid wordt samengewerkt en vinden allerlei datakoppelingen plaats: onder andere bij het uitgeven van paspoorten en rijbewijzen, verlenen van vergunningen, uitkeren van toeslagen en incasseren van boetes is data gemoeid.
Als consument zijn we gewend om te kunnen overstappen naar een concurrent of van een product/dienst af te kunnen zien. In het geval van overheidsdiensten is er geen alternatieve dienstverlener. En het afstaan van data is vaak geen vrije keuze. Wanneer je, als burger, geen informatie verschaft over je persoonlijke situatie, kom je niet in aanmerking voor een uitkering en krijg je ook geen vergunning voor de verbouwing van je huis.
De rol van data in overheidsbesluitvorming
Tegen die achtergrond en dat monopolie van de overheid krijgen beslissingen in de dataketen kleur. Met het opdelen van overheidsbesluitvorming in verschillende stappen komt de toepassing van data – en daarmee de dataketen – inclusief bijbehorende uitdagingen scherper in beeld. Zie hieronder in de visualisatie.
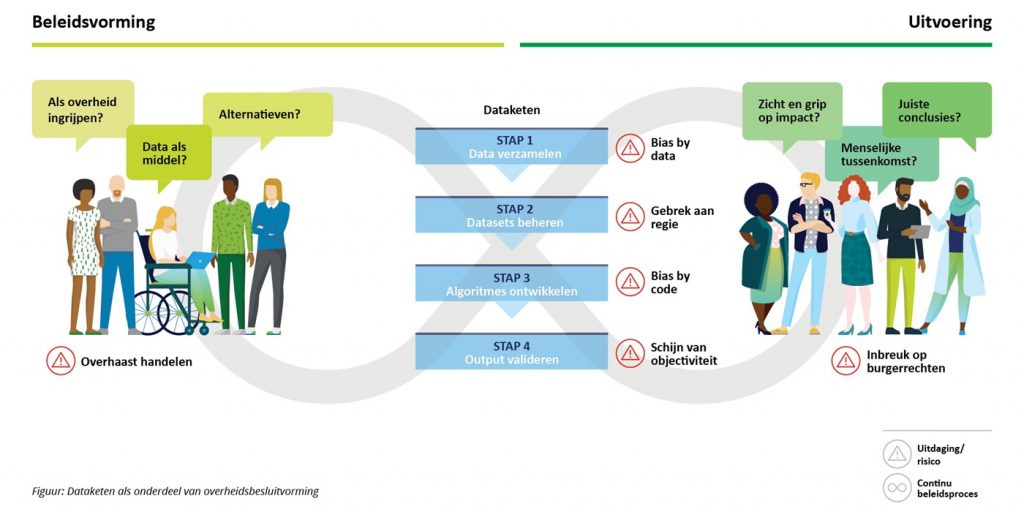
Bovenstaande visualisatie laat zien dat de dataketen start met en uitmondt in keuzes gemaakt dóór mensen óver mensen. Door de lange weg en vele beslismomenten van het begin tot het einde van dat proces kan de uitkomst heel anders zijn dan de intentie of zijn onvoorziene gevolgen mogelijk. Tijdens de beleidsvorming stuit de overheid op een aantal cruciale keuzes op het gebied van verantwoord datagebruik (zie ook ons eerdere artikel over de inzet van AI binnen de overheid).
Grip op datakwaliteit en -professionaliteit staat niet los van de bredere politieke debatten en weerbarstige uitvoeringspraktijk. De betrokkenheid van verschillende bestuursorganen en (publieke en private) informatiebronnen, maakt zorgvuldige gegevensuitwisseling en transparante besluitvorming tot een zeer complexe uitdaging. Onderstaande alinea’s volgen de onderwerpen en vragen die in de visualisatie worden weergegeven.
Beleidsvorming
- Moeten we als overheid ingrijpen?
Zoals gezegd klinkt de roep om actie bij maatschappelijke vraagstukken luid met als gevolg dat de druk op politici en bestuurders om met data aan de slag te gaan hoog is. De vraag of, en hoe, de overheid aan zet is, is (ook los van de datacomponent) een actueel en politiek thema. Allereerst is er de vraag of overheidsingrijpen noodzakelijk of gewenst is. En zo ja, dan volgt de vraag hoe je dan ingrijpt. Pas daarna komt het in te zetten middel – met als mogelijkheid een data-oplossing – in zicht.
- Moeten we data als middel inzetten?
Vanuit een idee van daadkracht of modern bestuur lijkt een datatoepassing vaak aantrekkelijk. Ook de wens tot innoveren of het benutten van technologische mogelijkheden kan een drijfveer zijn. Zeker bij data die al ‘in huis’ zijn, is de drempel laag om die in te zetten om zo als overheid daadkracht te tonen. De overheid beschikt over een enorme hoeveelheid data. De valkuil van ‘beschikbaarheid’ kan maken dat het middel een doel op zich wordt en dat niet meer nagedacht wordt over alternatieven die zelfs als ‘ouderwets’ worden beschouwd. Een mooi voorbeeld is het rode potlood bij verkiezingen. Deze ‘ouderwetse’ manier van stemmen is volgens deskundigen nog altijd het meest veilig.
- Is er behoefte na te denken over een alternatief?
De vraag om na te denken over een alternatieve oplossing en de verhouding tussen doel en middel is gerechtvaardigd. Denk aan: de vloer is nat; aha, een helder probleem, laten we gaan dweilen. Of: de vloer is nat; hoe komt dat eigenlijk: het dak is lek. Je kunt er dus ook voor kiezen om omhoog te kijken. Oftewel, niet direct naar een datatoepassing te reiken, maar eerst het grotere probleem in kaart te brengen. Om mogelijk tot de conclusie te komen dat het probleem een andere oplossing vraagt.
Dataketen
- Weten we de juiste datasets samen te stellen?
Mocht de uitkomst wél de wens tot een specifieke data-oplossing zijn, dan markeert dat stap 1 in de dataketen, met een duik dieper in de techniek: het verzamelen van data. De totstandkoming van een dataset is het startpunt en tevens zwaartepunt in de dataketen. Het verzamelen van data uit de databerg gebeurt met een bepaald doel. Dit vormt een belangrijk beslismoment, want als dit niet doordacht, doelgericht en ethisch verantwoord gebeurt, kan een onrepresentatieve dataset ontstaan. Meer focus van de politie op specifieke postcodes leidt bijvoorbeeld tot oververtegenwoordiging van bepaalde groepen of kenmerken in politieregisters. Volgens het principe van bias by data.
- Gebruiken we de datasets op juiste wijze?
Stap 2 is het beheren en onderhouden van datasets. Wanneer een dataset zorgvuldig is samengesteld voor een bepaald doel, kan daar vervolgens niet zomaar elke analyse op worden losgelaten. Niet alleen vanwege de verplichte binding met het doel, ook vanwege de samenstelling van de dataset: een dataset moet de juiste kenmerken hebben voor de data-analyse die je wilt maken. De selectie van beslissende kenmerken of variabelen (welke data heb je nodig?) is afhankelijk van de vraag. Datasets kunnen dus niet zonder meer hergebruikt worden en ook verrijking van datasets zonder regie wil je voorkomen.
- Datagedreven werken kan niet ‘een beetje’
Datagedreven werken is een werkwijze die niet deels kan worden doorgevoerd in een organisatie. Het kan alleen als iedereen meegaat, in alle lagen en op alle niveaus. Vaak is de uitdaging niet een gebrek aan kennis, maar het volledig kunnen doorvoeren van datagedreven werken. Wanneer medewerkers vasthouden aan eigen bestanden of mappenstructuren en procedures omzeilen door middel van workarounds vergroot dat de kans op gebrekkig databeheer, veiligheidsrisico’s en foutieve inzichten.
- Hoe ga je om met gradaties en foutmarges?
Een volgend beslismoment draait om manieren van dataverwerking. Waarvoor vaak een algoritme wordt ontwikkeld (stap 3). Algoritmes zijn breed te interpreteren als sets van regels en instructies die een computer geautomatiseerd volgt bij het maken van berekeningen om een probleem op te lossen of een vraag te beantwoorden. Zie bijvoorbeeld ook het rapport van de Algemene Rekenkamer (pdf).
De vraag waarvoor een algoritme wordt ontwikkeld gaat gepaard met het maken van keuzes en waardeoordelen: welke factoren wegen mee en hoe zwaar? Hoe ga je om met gradaties en foutmarges? Behalve bias by data is er namelijk ook bias by code. Willekeurigheid en historische – menselijke – vooringenomenheid kunnen worden gereproduceerd in datasets, maar ook in beslisregels. Het is niet altijd zwart/wit of een-op-een te vertalen in code. Over gradaties en prioriteiten en relevantie van persoonlijke- of contextfactoren valt te discussiëren. Het is van belang dat deze discussie intensief gevoerd wordt.
- Interpretatie vraagt kennis van context
Het valideren en weergeven van output vormt, tot slot, ook een cruciaal beslismoment (stap 4). De manier waarop cijfers in grafieken of tabellen inzichtelijk worden gemaakt of worden gevisualiseerd, is zelden neutraal. Door cijfers op een statistisch onjuiste manier weer te geven kan een onjuist beeld ontstaan. Daarnaast zijn bepaalde presentaties van de data niet voor iedereen even goed te begrijpen.
De schijn van objectiviteit en ‘meten is weten’ leidt tot risico’s. Het interpreteren van data-analyses is mensenwerk en vraagt om kennis over de context en om bescheidenheid (opnieuw: waarvoor is de analyse wel/niet geschikt). Het is niet eenvoudig om dit goed te doen en te organiseren. Zelfs met goede intenties kunnen onzorgvuldige dataverwerking- en presentatie kwalijke gevolgen hebben. Denk aan een grafiek met verkeerde schaal of een vergelijking van verkeerde grootheden.
Uitvoering
- Verbinden we aan de juiste conclusies de juiste consequenties?
Na het verzamelen van data (stap 1), het beheren van datasets (stap 2), het ontwikkelen van algoritmes (stap 3) en het valideren en visualiseren van output (stap 4) vinden de inzichten uit data hun weg naar de uitvoeringsorganisaties. Beleidsmakers maar ook baliemedewerkers moeten gaan handelen op basis van bepaalde conclusies uit systemen. Het moment waarop maatschappelijke en menselijke consequenties worden verbonden aan inzichten uit data (output), markeert het einde van de dataketen. Dat is het punt waar je van de wereld van dataprofessionals gaat naar de wereld van ambtenaren die in contact staan met de burgers en bedrijven die de overheid bedient.
- Menselijke tussenkomst is nodig
Neem een verzekering of toeslag die wordt geweigerd: “computer says no”. Maar voor zowel ambtenaar als burger is vaak niet duidelijk waarom dit zo is. Betekenisvolle menselijke tussenkomst en uitvoering op maat zijn daarom nodig. Net als uitlegbaarheid en omkeerbaarheid van automatische besluiten.
Maar ga er maar aan staan, onder invloed van de automation bias en dwingende ketenbesluitvorming. Automation bias gaat over een te grote afhankelijkheid van geautomatiseerde hulpmiddelen en beslissingsondersteunende systemen, veroorzaakt door de denkfout om meer waarde te hechten aan de suggesties die door een geautomatiseerd systeem gedaan worden, dan aan de suggesties van een mens. Dwingende ketenbesluitvorming gaat over een te grote afhankelijkheid van eerdere besluiten waardoor ‘bureaucratische kortsluitingen’ ontstaan, bijvoorbeeld wanneer foutieve gegevens moeilijk te corrigeren zijn en automatisch doorgegeven worden ter ondersteuning van diverse overheidstaken.
De bewijslast draait soms om: wie durft nog in te gaan tegen een conclusie van het systeem. Daarbij is het vooral de grip en het zicht dat verdwijnt – wie controleert, wie evalueert, wie regisseert et cetera. Dit raakt diverse organisaties. Voor de overheid heeft dit uiteindelijk gevolgen voor het functioneren van onze rechtsstaat.
Conclusie: veel gebeurt op verschillende niveaus en momenten
De conclusie is dat in overheidsbesluitvorming veel gebeurt op verschillende niveaus. Data-oplossingen vormen vaak een antwoord op bredere maatschappelijke uitdagingen. Hiervoor worden verbindingen gezocht tussen verschillende databronnen en organisaties.
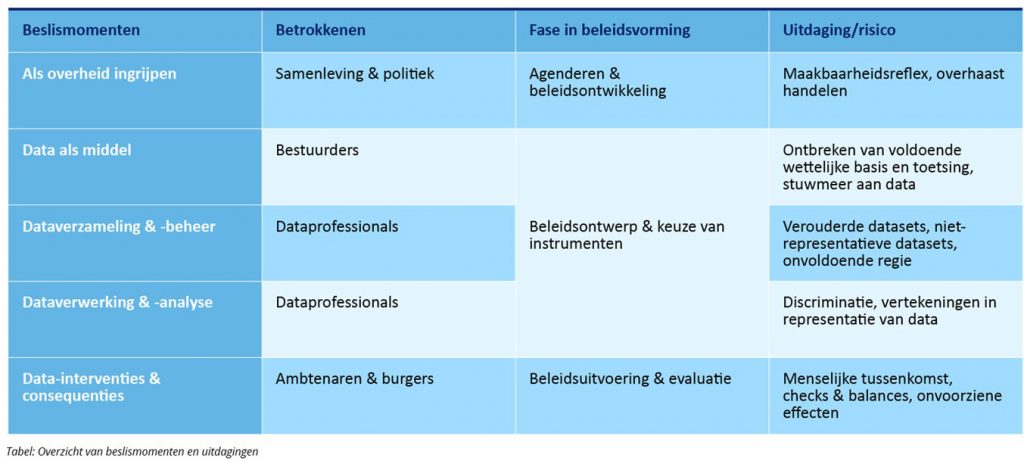
Er is inspanning nodig om dit verantwoord te organiseren. Het zichtbaar maken van keuzes rondom data-oplossingen is een belangrijke stap daarin. Er zijn meerdere beslismomenten waarop het mis kan gaan (zie tabel). En hoe het mis kan gaan, laat ook zien dat het ingewikkelder is dan alleen het maken van een goede keuze aan het begin van de keten. De analyse van cruciale beslismomenten in dataketens en het continue beleidsproces vormt de basis om hierna in te gaan op mogelijke oplossingen.
Over de auteurs: Hilary Richters is Director risk advisory en Lead digital ethics, Jeroen Jansen is Partner risk advisory en Ronald Brouwer is Senior manager risk advisory bij Deloitte.
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond