Hoe bouw je een moderne (marketing)-data stack?
Een cloud data warehouse met veel tools eromheen: dat is de moderne data stack. Wat kan zo’n data stack, welke aanbieders en mogelijkheden zijn er, en hoe werk je ermee? Lees het hier.
Eén grote stekkerdoos: zo zou je de moderne data stack kunnen omschrijven. Een cloud data warehouse met daaromheen verschillende specialistische Software-as-a-Service (SaaS) tools. Denk aan het samenbrengen van verschillende databronnen in een data warehouse of het operationaliseren van de data in marketing kanalen of andere systemen. Maar hoe stel je nou zo’n moderne data stack samen en op welke manier kan marketing hier van profiteren?
De moderne data stack bestaat uit verschillende best-of-breed oplossingen die ieder in een stuk functionaliteit voorzien. Zie het als een modulair systeem waarvan je de bouwblokken relatief eenvoudig kunt toevoegen of vervangen.
Data- en marketing-’technogloy stack’ groeien naar elkaar toe
Binnen de moderne data stack draait het niet alleen om het verzamelen van data in een centrale database (data warehouse), zodat alleen analisten of datawetenschappers hun werk kunnen doen. Datademocratisering – iedereen in de organisatie toegang tot goede data – en daarmee het kunnen operationaliseren van de data zijn steeds meer een vast onderdeel van het systeem, de stack.
Data uit het warehouse kunnen geautomatiseerd gekoppeld en geactiveerd worden in andere systemen. Dus de data gaan niet alleen het warehouse in, maar gaan er ook uit (operationalisatie). En dit is niet enkel een IT-feestje. Zo zijn er bijvoorbeeld tools waarmee niet-technische gebruikers eenvoudig doelgroepen bij elkaar kunnen klikken endeze geautomatiseerd kunnen delen met een marketing automation tool of Google Ads. Dit alles gebaseerd op de al aanwezige data in het data warehouse.
Ook zijn componenten als datatransformatie, governance en self-service business intelligence in de meeste gevallen een vast onderdeel binnen een modern systeem. Feit is dat de data- en de marketing-technology stack steeds meer naar elkaar toe groeien.
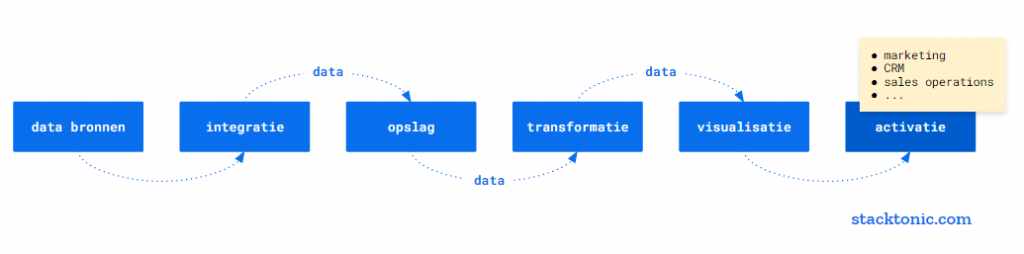
De opkomst van de moderne ‘data stack’
Aan de opkomst van de moderne data stack liggen een aantal ontwikkelingen ten grondslag:
- De verschuiving van on-premise naar cloud-native data warehouses (denk aan analytische databases zoals Amazon Redshift, Snowflake of Google BigQuery).
- De opkomst van SaaS-tools en services binnen cloudomgevingen die als bouwblokken op elkaar gestapeld kunnen worden.
- De opkomst van self-service business intelligence tools om data voor iedereen binnen een organisatie beschikbaar te maken (datademocratisering).
Het grote voordeel van de moderne data stack is dat het minder complex is geworden om een dergelijk systeem op te tuigen. Er is geen leger aan data engineers nodig om de bouwblokken op elkaar te zetten. Dit betekent overigens niet dat de rol van de data-engineer overbodig is geworden, integendeel. Het maakt het leven van de data engineer wel makkelijker.
Door tooling die gekoppeld kan worden in de stack kunnen eindgebruikers zelf met de data aan slag. Zowel het verkrijgen van inzichten als het operationaliseren van de data. En denk hierbij niet alleen aan de analisten maar ook aan de marketing-, sales- of operations-teams.
Een ander pluspunt is dat het systeem modulair is opgebouwd en de kosten vaak afhankelijk zijn van hetgeen je gebruikt. Voor zowel kleine als grote organisaties is een moderne data stack uitermate geschikt: er kan worden uitgebreid indien noodzakelijk, zowel qua schaal als functionaliteit. Maar uit welke onderdelen bestaat zo’n moderne data stack en waar begin je met bouwen?
De onderdelen binnen een modern ‘data stack’
Grofweg kun je de stack onderverdelen in onderstaande categorieën, welke ik stapsgewijs zal toelichten:
- Data integratie
- Dataopslag en -transformatie (ELT)
- Data-analyse en -visualisatie
- Data-activatie / -operationalisatie
- Data-governance en -kwaliteit
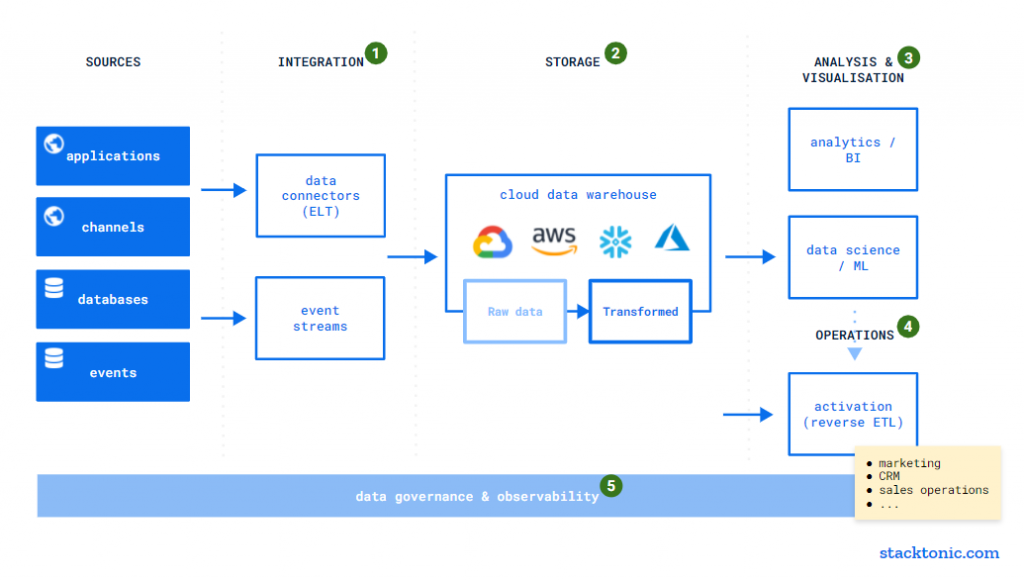
Per stap noem ik willekeurig een aantal aanbieders. Uiteraard is er meer keuze, de overzichten van Castor of Snowplow geven een meer compleet beeld van alle beschikbare SaaS-tools.
Dataintegratie: importeren van bronnen naar het ‘data warehouse’
Zoals al eerder genoemd is het een stuk eenvoudiger geworden om alle verschillende databronnen binnen je organisatie te koppelen met het data warehouse, zonder dat hiervoor een leger aan IT-specialisten en data-engineers nodig is. Dit neemt niet weg dat een data-engineer alsnog erg waardevol is.
De tools die op de markt zijn bevatten veelal 100 of meer kant-en-klare connectors. Denk aan het binnenhalen van marketingperformancedata uit Facebook, Google of Linkedin, maar ook CRM-data uit Hubspot, Salesforce of Shopify. Dit alles kan geconfigureerd worden zonder al te veel technische kennis. Al is het aan te raden om bij de inrichting iemand met kennis van zaken mee te laten kijken. Een aantal populaire aanbieders van data integratie-tools:
- Fivetran
- Stitch
- Adverity
- Airbyte (open-source)
- Mattilion
Deze tools sturen hebben als eindbestemming de analytische database in het cloud data warehouse.
Dataopslag en -transformatie
In het hart van de moderne data stack staat de (cloud-native) analytische database. Dit type databases zijn geschikt om snel enorme hoeveelheden data te kunnen analyseren. De meest bekende producten zijn:
- Snowflake
- Google BigQuery
- Amazon Redshift
- Azure Synapse
Bijna alle dataintegratie-tools benoemd onder het vorige kopje ondersteunen de bovenstaande databases als eindbestemming. Uit ervaring weet ik dat de keuze tussen de verschillende databases lastig kan zijn, al liggen de capaciteiten niet heel ver uit elkaar. Voor een uitstekende vergelijking raad ik aan dit artikel van Rogier Werschkull eens te bekijken.
Om de data consistent en bruikbaar te maken in de rest van de keten, is het belangrijk dat de data getransformeerd worden (denk aan het opschonen en samenvoegen). Omdat de cloud-native analytische databases zo krachtig zijn, is het prima mogelijk om de ongetransformeerde data (as-is) in te laden naar het data warehouse en datatransformatie pas een stap later op te pakken. Van ETL naar ELT (Extract, Transform Load naar Extract, Load, Transform). Dit haalt een stuk functionaliteit weg bij de dataintegratie-tools uit het vorige hoofdstuk. Alle datatransformatie komt daarmee op één plek te liggen in plaats van deels in het integratieproces en deels in het data warehouse.
Een veelgebruikte datatransformatie-tool die het leven van de data-engineer en de analisten een stuk makkelijk maakt, is dbt.
Data-analyse: naar een ‘self-service’ model
Data beschikbaar maken voor iedereen binnen de organisatie is een belangrijke manier om een data-driven cultuur te creëren. Dus ook zonder technische kennis van bijvoorbeeld SQL moet het eenvoudig zijn om de gewenste data te verkrijgen. Het is dus zaak om een moderne business intelligence tool te selecteren die integreert met cloud-native databases. De meeste tools bieden inmiddels self-service functionaliteit waarin de eindgebruiker zijn of vragen vragen met behulp van data op kan lossen. Denk aan het eenvoudig verkennen van databronnen of verder kunnen verdiepen van informatie in bestaande rapportages. Bekende aanbieders zijn:
- Looker
- Tableau
- PowerBI
- Qlik
- Apache Superset (open source)
- Metabase (open source)
Maar hoe mooi zou het zijn om niet enkel te kunnen analyseren maar de data ook direct en geautomatiseerd te kunnen gebruiken in bijvoorbeeld je marketingkanalen of CRM, en daarmee dus eigenlijk ook onderdeel te worden van de marketing-technology stack?
Dataoperationalisatie: activeer data vanuit het ‘data warehouse’
In 2021 zijn er enorm veel investeringen geweest in partijen die tools ontwikkelen om data vanuit een data warehouse tw kunnen operationaliseren. Dit wordt ook wel Reverse ETL genoemd. Reverse ETL doet inderdaad precies het tegenovergestelde als ETL (Extract, Transform, Load): data uit je data warehouse weer terugbrengen naar de bron of andere systemen.
Dit heeft niet enkel voordelen voor marketing, maar bijvoorbeeld ook voor sales of HR. Denk aan het automatisch aanmaken van Google Ads of Facebook audiences, aanvullen van inzichten in een CRM-systeem (360º customer view) of het personaliseren van e-mailcampagnes. Tools zijn bijvoorbeeld:
- Census
- Hightouch.io
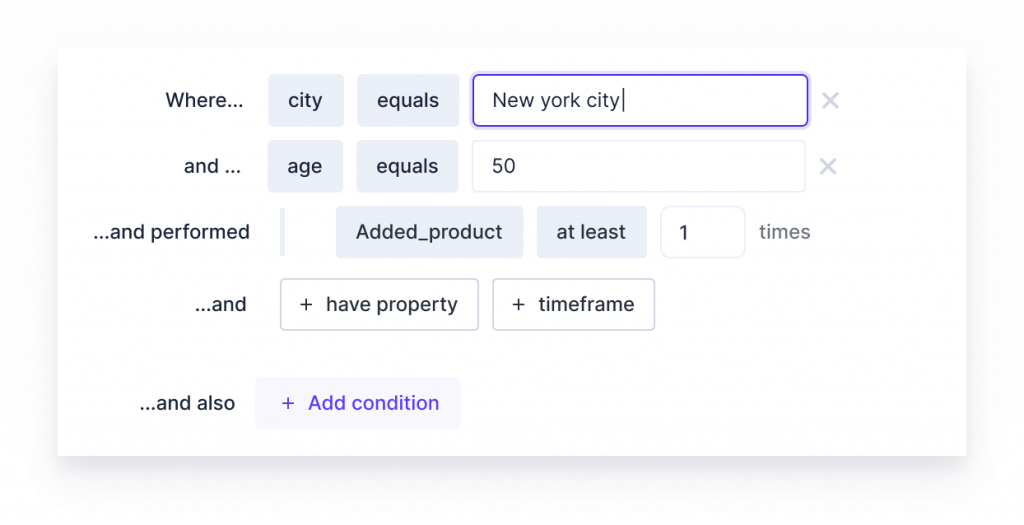
Hightouch.io heeft bijvoorbeeld een ‘audience builder’ waarmee je ook zonder technische kennis doelgroepen bij elkaar kunt klikken en kunt koppelen met marketingkanalen en andere ’tools’.
Reverse ETL zorgt er eigenlijk ook voor dat de moderne data stack de concurrentie aangaat met stand-alone Customer Data Platforms (CDP’s). Je zou de moderne (marketing-) data stack dan ook kunnen zien als een headless CDP.
Data-‘governance’ en -kwaliteit: inzicht in je data
De laatste maar zeker niet de minste stap: data-governance en datakwaliteit. Vertrouwen in de data is de namelijk een van de belangrijkste componenten om het hele systeem te laten slagen. Dit is dan ook een categorie waar momenteel veel ontwikkeling plaatsvindt en die in 2022 een vogelvlucht zal namen. Grofweg zijn er in deze categorie twee type tools. De en de data quality & observability tools.
Data catalogs
Hoe weet je nou uit welke databron een bepaalde dashboard-metric komt? Of als we het omdraaien, als tabel X gewijzigd wordt, op welke dashboards of systemen heeft dit potentieel invloed? Om dit in kaart te brengen zijn er data catalogs. Deze tools brengen verschillende databronnen, -tabellen, -dashboards of andere makers of gebruikers van data in kaart en linken deze aan elkaar (data lineage). Daarnaast is er vaak de mogelijkheid om documentatie toe te voegen en de hele catalogus te doorzoeken. Om een aantal tools te noemen:
- Atlan
- Apache Atlas
- Amundsen
- DataHub
Data quality & observability
Naast inzicht en documentatie, kunnen de verschillende databronnen ook automatisch gemonitord worden. Dit kan enerzijds op basis van machine learning die automatisch afwijkingen in de data constateert dan wel het handmatig toevoegen van controles (mist er bijvoorbeeld een cruciaal veld of is de data in de afgelopen 24 uur wel bijgewerkt). Bij afwijkingen kunnen er alerts verstuurd worden, bijvoorbeeld via email en/of Slack. Tools zijn:
- Monte Carlo
- Soda
Stap voor stap: begin met een ‘business case’
De beste tip die ik kan geven: begin met een business case. The moderne data stack leent zich er uitstekend toe om op die manier te werk gegaan. Niet elke bron hoeft vanaf het begin gekoppeld te worden. Begin daarom met een of een aantal eerste business cases en bouw vervolgens verder. Op die manier kun je snel waarde en draagvlak creëren. Laat ook zien dat het niet alleen een IT-aangelegenheid is. Met de juiste set-up zou de output laagdrempelig beschikbaar moeten zijn voor de hele organisatie, zowel qua inzichten als het operationeel maken van data binnen alle onderdelen van de organisatie.
In het begin zullen er zeker een aantal fundamentele keuzes gemaakt moeten, maar vervolgens kan er stapsgewijs uitgebreid worden. Doe in deze fase gedegen onderzoek, betrek de juiste mensen en zorg voor de juiste kennis aanwezig is om zo een solide fundament neer te zetten.
Over de auteur: Krisjan Oldekamp is Freelance marketing technology & data consultant via Stacktonic.
Op de hoogte blijven van het laatste nieuws binnen je vakgebied? Volg Emerce dan ook op social: LinkedIn, Twitter en Facebook.
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond