Data-interpretatie: de meest gemaakte fouten
Hoe behoeden we onszelf ervoor geen verkeerde conclusies uit data te trekken? Fluctuaties van resultaten zouden eigenlijk altijd vanuit langetermijnoogpunt bekeken moeten worden. Check met dit artikel of jij als datagladiator van de Romeinse keizer een ‘thumbs up’ of ‘thumbs down’ zou krijgen. Wat zijn de meest gemaakte fouten als het gaat over de interpretatie van data?
Conversie-optimalisatie en variantie
Soms wordt er gesproken over het fenomeen seasonality. Bij expected value berekeningen in poker noemen ze dit variance. In games wordt het de Random Number Goddess (RNG) genoemd: ‘the supreme being who reigns over all moments of chance’. De bekende statisticus Nassim N. Taleb heeft er een boek over geschreven genaamd ‘Fooled by Randomness’. Waar doel ik hier op?
Het feit dat een trendlijn zich op korte termijn op onverklaarbare wijze ongebruikelijk kan bewegen.
En dan hebben we het bijvoorbeeld over een sessie- of conversietrendlijn. De waardeverandering van een aandeel gaat immers ook niet precies 1/365e van zijn jaartrend per dag omhoog of omlaag. Dit gaat in cyclische bewegingen. Het kan immers zo zijn dat het aandeel in de eerste drie maanden keldert als een baksteen, uiteindelijk herstelt, en aan het eind van het jaar vier procent meer waard is geworden.
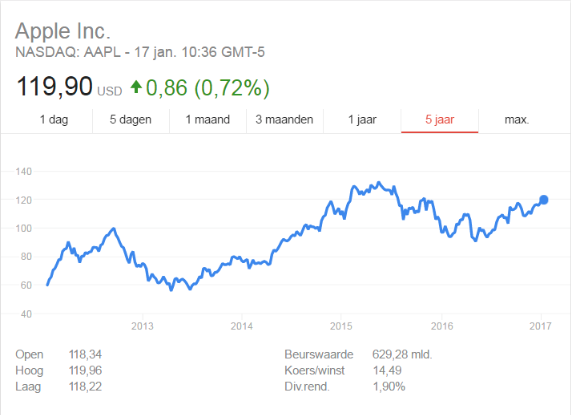
De trendlijn van het aandeel Apple sinds 2012 – geheel in cyclische beweging
“In the short run, the market is a voting machine but in the long run, it is a weighing machine.” -Benjamin Graham
Als datawetenschapper mag jij je natuurlijk niet laten leiden door kortetermijnvariantie. Op korte termijn mogen uitslagen enorm variëren, op de voorwaarde dat uitslagen op lange termijn uitstekend blijven.
Wat zijn de meest gemaakte fouten als het gaat over de interpretatie van data? Hieronder een aantal voorbeelden waar je je ongetwijfeld wel eens aan schuldig hebt gemaakt. Geeft natuurlijk helemaal niets, maar als je marketingstrategie gaat baseren op door jou zelf gegenereerde data, dan kun je maar beter zorgen dat de conclusies die je daaruit trekt ook valide en betrouwbaar zijn, eens?
Conclusies trekken op basis van Low Sample Size Data
We kennen allemaal mensen die één keer in de zoveel tijd met een opmerking als onderstaand komen:
- Deze week vallen de resultaten van campagne X tegen. Daar waar we vorige week nog 25 conversies hadden, hebben we er deze week 19, wat een daling is van 26 procent! Kun je dit verklaren?
- Afgelopen maand is het budget wat teruggeschroefd, en de absolute aantallen conversies in totaal zijn met 5,6 procent afgenomen van 29 naar 27. Het aantal Facebook likes is zelfs gedaald tot 59. Kun je dit uitzoeken?
Hiermee wil ik benadrukken dat er reden tot paniek kan zijn, maar dat uitslagen vooralsnog natuurlijk variëren. In de testperiode zijn er kennelijk zo weinig conversies om te meten, dat een goede conclusie trekken eigenlijk onmogelijk is. Een echte conclusie zou dan moeten zijn dat de periode waarover vergeleken wordt te kort is.
Als A/B-tester kun je van te voren een schatting van volume maken. Die hoeft niet correct te zijn, maar geeft je wel een indicatie. Het is namelijk zonde om erachter te komen, nadat een test live heeft gestaan, dat de hoeveelheid conversies te laag is om er een zinnige conclusie uit te trekken. Doe dus je best om dit zo goed mogelijk te voorkomen of met een beter voorstel te komen.
Soms moet je gewoon accepteren dat de conversieresultaten aan de lage kant zijn, maar laat je dan niet verleiden tot een uitspraak die eigenlijk onwaar is.
Conclusies baseren op data uit een te korte tijdsperiode
Data halen we uit een bepaalde datarange. In die datarange geldt een bepaalde trendontwikkeling met een bijhorend piek en dal: het hoogste en het laagste punt in onze trendlijn.
Een tijdje geleden kwamen er een aantal e-mails in mijn mailbox voorbij, waarin resultaten werden vergeleken. Meerdere keren stond er ‘dit is de beste dag tot nu toe’, de andere dag was het ‘slechtste dag tot nu toe’. Wat bleek? De tijdsperiode waarmee de resultaten werden vergeleken was enorm kort. Geen wonder dat je dan heel snel komt tot ‘de beste of slechtste resultaten tot nu toe’.
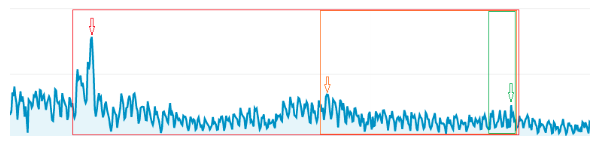
In de groene datarange zit de piek van de trendlijn bij het groene pijltje. Verbreden we de datarange, kunnen we een hogere piek zien, in dit voorbeeld in zowel de oranje als de rode periodes.
Verbreden we de periode waarnaar we kijken, dan wordt de kans een stuk kleiner dat uitslagen ‘de slechtste of beste tot nu toe’ worden. En zijn ze dat wel, dat is het ook echt een betere of slechtere prestatie. Positieve en negatieve uitslagen worden vaak aangedikt. Wat je je moet afvragen is of deze lichte dramatisering wel gegrond is.
Conclusies trekken op basis van incomplete data
Conclusies trekken uit incomplete data komt ook nogal eens voor. Als voorbeeld: er zijn drie manieren (paden) om van een landingspagina naar een signup formulier te komen. Dit kan middels twee call-to-action buttons en een link op je landingspagina.

Variant B met de belangrijkste call-to-action boven de vouw.
Stel, ik heb een originele variant met een call-to-action onder de vouw, en andere varianten waar de positie van de belangrijkste call-to-action anders is (bijvoorbeeld boven de vouw). Als meetdoel stel ik het aantal unieke kliks op de belangrijkste call-to-action-button in. Uit resultaten blijkt dat er een uplift te zien is. In mijn enthousiasme wil ik deze resultaten vervolgens rapporteren. Maar kun je deze conclusie wel trekken, enkel op basis van de click through rate van de belangrijkste call-to-action-button?
In dit voorbeeld meten we de totale doorstroom en de verhouding daarvan via de verschillende mogelijkheden op een pagina niet goed door. Kortom, je weet niet of de totale effectieve doorstroom eigenlijk wel is toegenomen, of dat je aanpassingen enkel een verschuiving in de verhouding van de doorstroom teweeg hebben gebracht. Dit kan positief zijn, maar verbetert de ‘net gain’ uiteindelijk niet.
Het kan natuurlijk voorkomen dat je er naderhand achterkomt dat je niet alle paden goed te hebben door te meten. Geen ramp! Het is natuurlijk geen schande om een test te herhalen, zeker als de resultaten dan wel bruikbaar zijn.
Conclusies baseren op resultaten zonder significantie
Wij verbazen ons nog zeker een paar keer per jaar hoeveel resultaten worden gerapporteerd zonder dat er een goede significantieberekening bij wordt gegeven. Waarom gebruiken we significantie (of Bayesiaanse statistiek) ook alweer? Omdat we willen uitsluiten dat de conclusie die we trekken over uitslagen op toeval berusten (lees: random variantie).
Een uitslag die positief significant is, is dus in feite statistisch getoetst om uit te wijzen of resultaten er echt toe gaan doen, of niet.
Dit heet niet voor niets officieel een ANOVA test, ofwel een ANalysis Of VAriance. Het is een statistische toetsing voor onderzoekspopulaties verdeeld onder meerdere groepen. Kortom, zijn uitslagen significant op het 90-procentlevel, dan kun je er met meer zekerheid van uitgaan dat een uitslag niet op toeval berust en er sprake is van een zeker verband tussen jouw aanpassingen en de resultaten die je te zien krijgt.
Conclusie
Het is natuurlijk heel fijn dat uitslagen variëren en dat onze doelgroep heterogeen is, want dat maakt het immers mogelijk dat A/B-testing voor optimalisatie kan zorgen. De juiste conclusies trekken uit data is enorm van belang. Voer je aanpassingen door die eigenlijk fout positief zijn, dat kost dat jou en je webbouwer tijd en geld, zonder dat het echt iets oplevert. Laat jezelf daarom niet misleiden door toeval en variantie.
*) Dit artikel is tevens gepubliceerd op de website van Traffic Builders.
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond