Rough-and-ready? Waarom je bij belangrijke beslissingen beter zelf analyses kunt uitvoeren op je Google Ads experimenten
Meten is weten. Google weet dat maar al te goed en biedt daarom al een paar jaar de mogelijkheid om experimenten uit te voeren in Google Ads. Denk hierbij aan bijvoorbeeld het testen van twee advertentiegroepen met verschillende zoekwoorden.
Maar weet je eigenlijk hoe Google test of je experiment een significant verschil vertoont? Best belangrijk om te begrijpen, want op basis van de uitkomsten van die test wordt vaak gekozen om met de best presterende advertentie door te gaan. Bij kleinere campagnes zijn dergelijke analyses niet super impactvol, maar bij grote budgetten kunnen dergelijke beslissingen honderden tot duizenden euro’s kosten of opleveren. In deze gevallen wil je honderd procent zeker zijn van je besluit. In dit artikel duiken we in de testmethode van Google, maar dan wel mét een kritische blik.
Onder de motorkap van Google Ads
Binnen Google Ads heb je als online marketeer de mogelijkheid om verschillende soorten campagnes uit te voeren. Dit kan een campagne met simpele tekstadvertenties zijn, maar bijvoorbeeld ook een Google Shopping campagne. Sinds 2016 is het mogelijk om campagne experimenten te starten. Deze functionaliteit geeft ons de mogelijkheid om verschillende advertentiegroepen, zoekwoorden, landingspagina’s of advertenties tegen elkaar te testen. Op deze manier kunnen we kijken welke advertentie tot bijvoorbeeld de meeste websitebezoekers leidt, of welke advertentie het beste mensen overhaalt tot het kopen van producten. In de meeste gevallen is zo’n experiment een A/B test, waar twee advertenties op één onderdeel verschillen. Vervolgens krijg je een heldere uitslag: een van de twee advertenties leidt significant tot meer verkopen, of niet. Is er een advertentie die het significant beter doet, dan kiezen we veelal voor die optie.

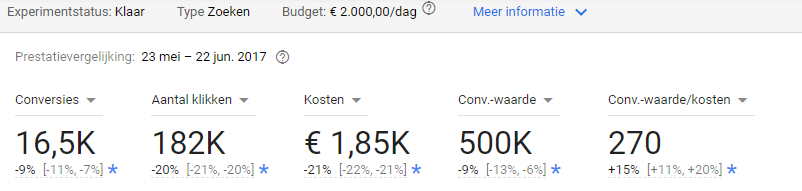
Een voorbeeld van een experiment. In dit geval waren er significant minder conversies in het experiment in vergelijking met het origineel.
Duidelijk, maar hoe komt Google eigenlijk aan die uitkomst? Hoewel het op het eerste gezicht lijkt op een black box, is het dat (gelukkig) niet. Google legt op een supportpagina uit dat het onder andere gebruik maakt van Jackknife resampling, een methode die veel lijkt op de bekendere t-test. Jackknife sampling is een methode die in 1949 is uitgevonden en in 1958 is uitgebreid door John Tukey, een beroemde wiskundige die ook bekend staat om de ontwikkeling van de box plot. Tukey koos voor de naam jackknife, naar het grote zakmes, omdat de techniek (net als het mes) rough-and-ready is. Oftewel, de methode is in bijna alle gevallen te gebruiken. Tukey’s methode is dus erg flexibel. Zo kan het een oplossing vinden voor uiteenlopende problemen.
Wat is Jackknife resampling?
Google heeft een aantal heldere redenen om voor deze methode te kiezen. De eerder beschreven flexibiliteit van de methode is er één, maar daarnaast is deze methode ook erg effectief in het detecteren van en omgaan met uitschieters (outliers) en het reduceren van systematische fouten (bias) in schattingen (estimates). Veel statistische termen, maar Google kiest hier dus voor een model dat om kan gaan met vrijwel alle data. Ook data welke niet ‘perfect’ is en uitschieters bevat kan zo worden gebruikt. Dit geeft Google en de marketeer een groot voordeel, want data is nagenoeg nooit perfect!
Daarnaast heeft Google nog een methode om kleine observatie fouten eruit te halen: bucketing. Met bucketing wordt de data opgesplitst met een vaste interval. Wanneer waardes dicht bij elkaar zitten en binnen dezelfde interval vallen, dan worden ze in dezelfde ‘emmer’ geplaatst. Bij temperatuur zou je bijvoorbeeld een interval kunnen nemen van 5 graden. De waardes tussen 0 en 5 vallen dan in dezelfde emmer. Zo wordt de data verder genormaliseerd. Misschien ken je misschien de normale verdeling nog van wiskunde. Wanneer data normaal verdeeld is, bevindt het gros van de data zich rondom de gemiddelde waarde. We zien minder datapunten naarmate we verder van de gemiddelde waarde komen. Dit geeft de welbekende belvorm, zoals in het figuur hieronder.
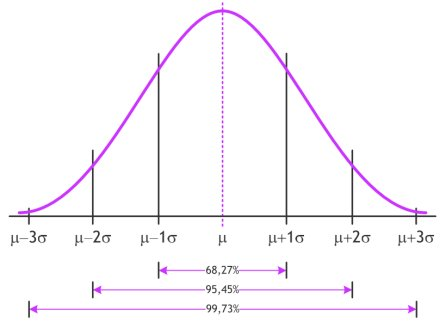
De belvorm komt terug in iedere normale verdeling
Veel statistische testen verwachten dat de data normaal verdeeld is. Toch kan het voorkomen dat dit niet het geval is. Google heeft dit dus opgelost met bucketing. Deze methode zorgt toch voor een grofweg normaal verdeelde dataset die kan worden gebruikt.
Validiteit
Google heeft duidelijk haar best gedaan om experimenten toegankelijk te maken voor het gros van de Google Ads gebruikers. In mijn ogen is dat bewonderenswaardig, maar is de test op deze manier wel valide? Experimenten worden veel gebruikt om bijvoorbeeld verschillende advertentieteksten te testen. De uitslagen van deze test worden vervolgens gebruikt om toekomstige campagnes beter in te steken. De validiteit van deze test is daarmee erg belangrijk, aangezien ze worden meegewogen in onze beslissingen om campagnes te verbeteren.
Google moet een aantal zaken op orde hebben om een valide t-test uit te voeren. De eerder genoemde normale verdeling is er een van. Daarnaast moet Google de te testen advertenties at random laten zien aan gebruikers om representatieve data te krijgen. Stel, Google levert advertentie A steeds uit aan personen die allemaal in-market (mensen die geneigd zijn het product snel te kopen) zijn voor het te verkopen product en advertentie B aan mensen die dat niet zijn, dan is de steekproef niet representatief. Dan ligt een verschil in uitkomst niet per se aan de verschillende advertenties, maar aan de mensen die zijn bereikt. Bij advertenties met een beperkt budget maakt Google gebruik van Jackknife resampling en bucketing om hiervoor te corrigeren indien nodig. Bij een lager budget is het lastiger om at random advertenties te tonen aan gebruikers, gezien een lager budget minder vertoningen betekent.
Ook moet de steekproef groot genoeg zijn om een conclusie te kunnen trekken over de veel grotere populatie. Er kleeft helaas een nadeel aan een grote steekproef. Wanneer de steekproef groot is, dan zijn er bijvoorbeeld meer dan duizend observatiepunten voor ieder testobject. In zo’n geval zijn de resultaten vrijwel altijd significant. Ook als het verschil zelf (in bijvoorbeeld conversies) relatief klein is. Daarom is het ook verstandig om jezelf vooraf af te vragen wat het minimale effect zou moeten zijn voordat je actie gaat ondernemen.
Beter meten
Daarmee komen we bij de volgende vraag; hoe relevant is die significantie? Bij experimenten met een grote steekproef is de significantie eigenlijk niet zo interessant. Het is goed om te weten dat het experiment statistisch gezien een verschil vertoont dat voor 95% zekerheid niet aan kans ligt, dat betekent een significant verschil. Maar wat als we een andere methode loslaten op onze dataset? Bij belangrijke beslissingen wil je honderd procent zekerheid, en Google’s t-test geeft dat eigenlijk niet volledig.
Lineaire regressie
Wellicht vindt een lineair regressie model een verschil dat niet significant is, maar ook dit model is gevoelig voor grote steekproeven. Dit model is namelijk gebaseerd op dezelfde principes als de t-test. Wel geeft een lineaire regressie de mogelijkheid om meerdere verklarende variabelen toe te voegen om bijvoorbeeld een stijging te verklaren. Stel je voor dat je een weer-gerelateerd product verkoopt, dan zou een verandering in conversies mogelijk het gevolg zijn van het weer en niet per se door de veranderde advertentie. Op die manier krijg je meer controle in het achterhalen van beïnvloedende factoren.
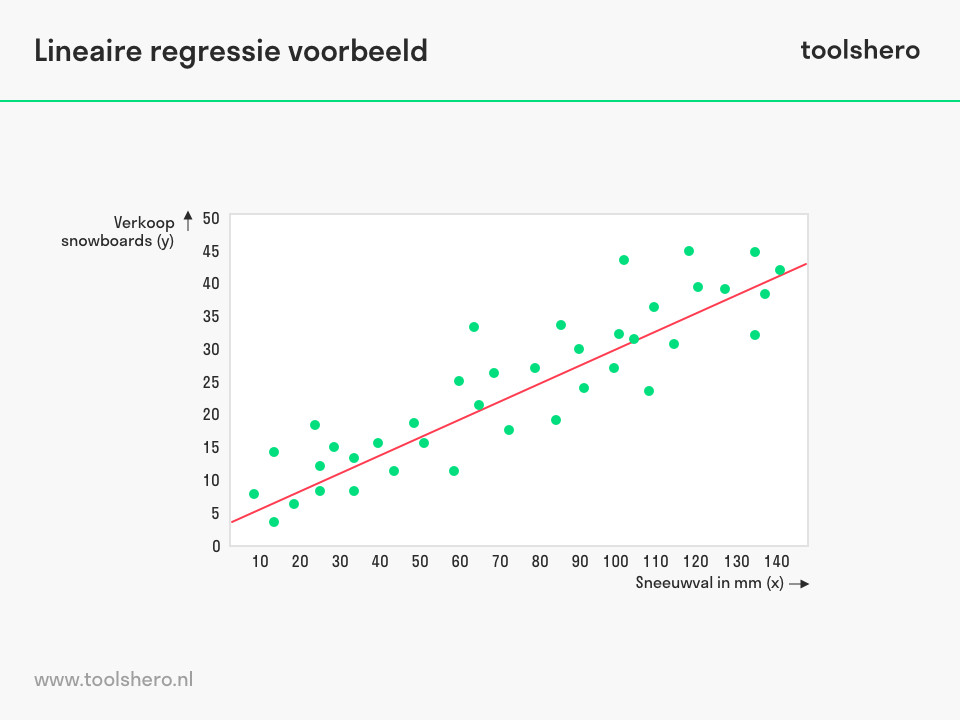
Een lineaire regressie waar de verkoop van snowboards wordt getest als een gevolg van sneeuwval.
Een ander veel gehoord voordeel van een lineair regressiemodel is dat de effectgrootte kan worden berekend, maar dit zou in principe ook mogelijk zijn met de uitkomsten van een t-test. Wel mis je bij een t-test de mogelijkheid om de effectgrootte van verklarende variabelen te berekenen, en te kijken hoe groot het effect van deze variabelen is. Een regressie analyse kan ons meer specifieke verklaringen geven dan een simpele t-test.
Monte Carlo methode
Nog beter, en ook beschreven in het onderzoek van Lin, Lucas & Shmueli (2013), is gebruik te maken van methodes die (heel) veel verschillende steekproeven van de data maakt. Een bekende methode die zo werkt is de Monte Carlo methode. De naam refereert naar de casino’s in Monaco, omdat je in het casino te maken hebt met veranderende startcondities. De ene keer krijg je bijvoorbeeld betere kaarten geschud dan een andere keer. De Monte Carlo methode doet iets soortgelijks. Als het ware maakt de methode meerdere steekproeven van de bestaande data die allemaal net even verschillen in startcondities. Vaak gaat het om duizenden verschillende steekproeven met verschillende startcondities, waardoor veel mogelijke scenario’s mee worden genomen in de analyse. Ook worden onzekerheden beter meegenomen. Daarnaast wordt de significantie van de uitslag relevanter. Door de duizenden steekproeven die verschillen in grootte is de grootte van de totale dataset niet meer een beïnvloedende factor. Helaas is de Monte Carlo methode niet geïmplementeerd in Google Ads, maar deze is wel toe te passen in statistische programmeertalen als Python of R.
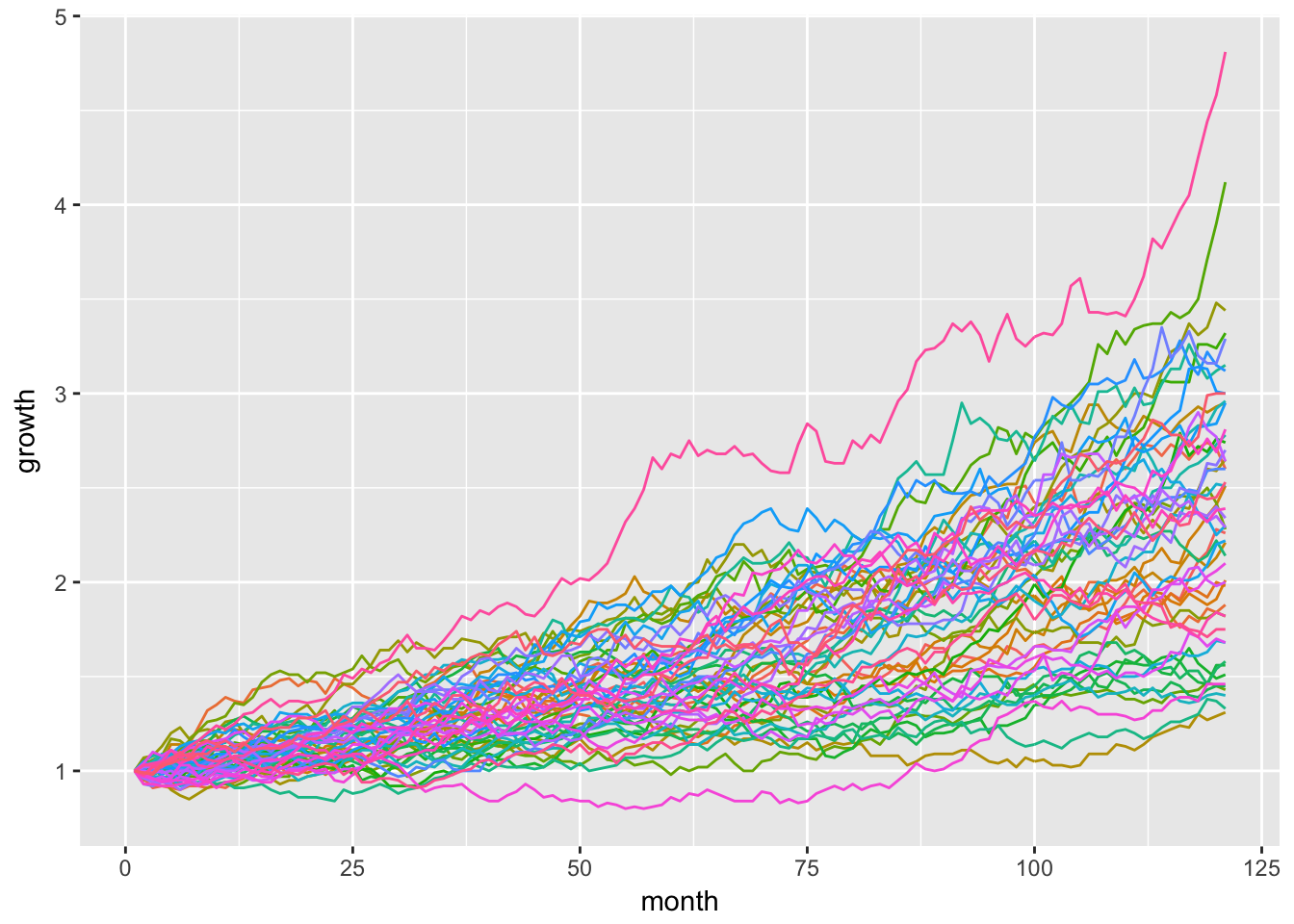
Voorbeeld van een Monte Carlo simulatie met alle mogelijke uitkomsten die het berekent.
De Monte Carlo methode klinkt wellicht lastig (en vereist ook wel meer kennis van statistiek), maar is relatief gemakkelijk op te zetten. In statistische programmeertalen als Python of R kan een analyse worden gecodeerd die vervolgens kan worden toegepast op dezelfde typen datasets, wat het herbruikbaar maakt. Daarmee is (bijvoorbeeld) de Monte Carlo methode op de lange termijn een mooie opstap om ook meer geavanceerde tests te gaan implementeren.

Rstudio is een statistische taal waarmee je analyses kunt coderen
Google’s geavanceerde t-test is een prachtig beginpunt om experimenten te toetsen op hun prestaties, maar zou niet ook meteen het eindpunt moeten zijn. Zeker niet wanneer deze worden meegenomen in strategische beslissingen. Het gebruiken van meerdere methodes om hetzelfde probleem te toetsen is een vorm van validatie. Met die validatie door meerdere testen kun je met meer zekerheid beslissingen nemen die een groot verschil kunnen maken, en zo campagnes efficiënter maken. Iets wat de moeite waard is wanneer je campagnes beheert waar grote budgetten doorheen gaan.
Trend gevoelig
Tot slot is het opvallend dat Google gebruik maakt van een methode die niet echt rekening houdt met trends. En dan heb ik het niet over een trend op het gebied van statistische methodes, maar over trends over tijd die je data kunnen beïnvloeden. Neem bijvoorbeeld seizoensgebondenheid (ook wel seasonality). Wanneer een product onderhevig is aan bijvoorbeeld de seizoenen, dan kan het zijn dat uitkomsten worden versterkt (of juist verminderd) als gevolg van het moment in het jaar. Dit is iets waar Google al rekening mee kan houden in Smart Bidding, maar niet voor wordt gecorrigeerd door de t-test die Google toepast op je data. Het zou erg logisch zijn om dergelijke filters ook toe te passen in de analyse van je experiment.
Verder zijn er nog vele tijd-gerelateerde zaken die je data kunnen beïnvloeden. Stel, je doet marketing voor een vliegtuigmaatschappij. Als het onwaarschijnlijke gebeurt en een toestel neerstort, dan gaat zo’n zeldzame gebeurtenis veel impact hebben op je bedrijfsvoering. Een vector autoregressive model (VAR model) is veel geschikter om dan de grondslag van veranderingen in je data te vinden dan een simpele t-test.
Nu zijn VAR modellen niet erg makkelijk in gebruik, zag ook Google. Zij kwamen met een soort alternatief, het Bayesian Causal Impact Model. Ook daar kun je het startmoment van ‘shocks’ aangeven en testen of deze shocks een significant effect vertonen op je data. Een shock hoeft in dit geval ook niet luguber te zijn, dit zou al het aanzetten van een campagne kunnen zijn. Helaas zien we zo’n geavanceerd model nog niet terug in de Google producten zoals Ads. Google heeft dit model relatief recent ontwikkeld en uitgebracht, waardoor het voor nu enkel nog beschikbaar is als toepassing in R-studio. Hopelijk gaat Google dit soort zelf-ontwikkelde modellen uiteindelijk ook implementeren in de marketing suite.
Het voordeel dat dit model beschikbaar is als R-studio toepassing is dat je in principe maar één keer de analyse hoeft te schrijven. Vervolgens kan dit model gemakkelijk gelijkwaardige datasets analyseren.
Upgrade je analyse
Wanneer je een experiment doet waar niet heel veel vanaf hangt, dan is de methode van Google hoogstwaarschijnlijk prima. Maar doe je experimenten op campagnes waar veel budget doorheen gaat, dan wil je misschien je analyse gaan upgraden.
Google biedt ons een mooi beginpunt om iets te kunnen zeggen over verschillende advertenties en hun prestaties. Echter, het zou ook echt een beginpunt moeten zijn bij belangrijke en impactvolle beslissingen. De achterliggende methode is eigenlijk te basaal om harde conclusies aan te verbinden. Daarvoor zouden combinaties van methodes nodig zijn.
Bij Merkle Nederland kijken we al welke klanten voordeel zouden hebben aan data analyses waar bijvoorbeeld de impact van het weer wordt bekeken. Ook seizoensgebondenheid komt terug in sommige analyses. Wanneer deze analyses goed in elkaar zitten, dan weten we ook wat voor advertenties op welke momenten het meest geschikt zijn. En dan zijn we echt in staat om people-based marketing te implementeren.
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond