Wat is crawl budget en moet ik me daarmee bezighouden?
Crawlen, het is datgene wat Google doet om de inhoud van je site te indexeren. Als je website niet goed gecrawld kan worden, heeft dit grote gevolgen voor de vindbaarheid. Crawl budget is een niet veel gehoorde term, echter we merken dat, vooral grote, websites hier vaak kansen laten liggen. In deze blog vier insider tips voor techies.
Wat is crawl budget?
Dagelijks crawled Google een aantal pagina’s op je website. Dit aantal, ook wel het crawl budget genoemd, kan per dag licht variëren. Op de lange termijn blijven deze afwijkingen vaak echter in lijn. De hoeveelheid pagina’s dat een zoekmachine crawled is afhankelijk van een aantal zaken, zoals de grootte van je website en het aantal links naar je website. Via Search Console kun je het crawl budget voor jouw pagina terugvinden, in onderstaande afbeelding zie je een voorbeeld.
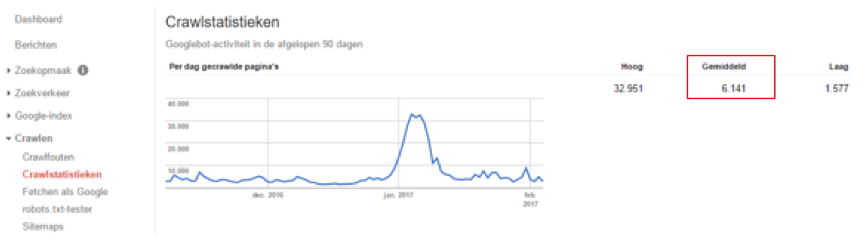
Om snel te kunnen zien of het crawl budget op jouw website geoptimaliseerd kan worden, kun je de volgende zoekopdracht in Google uitvoeren (protocol afhankelijk): “site:website.nl”. Daarna zie je het totaal aantal geïndexeerde pagina’s in Google. Zie onderstaande afbeelding voor het voorbeeld:
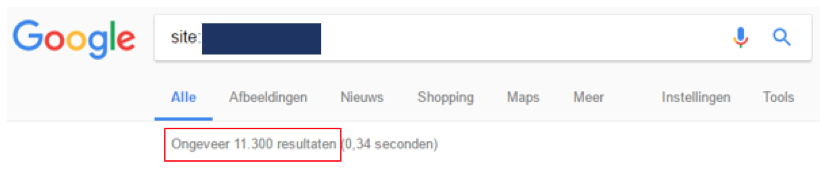
Als dit enorm afwijkt van het gemiddelde aantal gecrawlde pagina’s uit de Search Console, dan kun je de conclusie trekken dat niet elke pagina dagelijks wordt gecrawld. Hierbij is het goed in je achterhoofd te houden dat het dagelijkse aantal gecrawlde pagina’s door Google afhankelijk is van meerdere factoren zoals autoriteit, de grootte van de website etcetera.
Waarom moet ik het crawl budget optimaliseren?
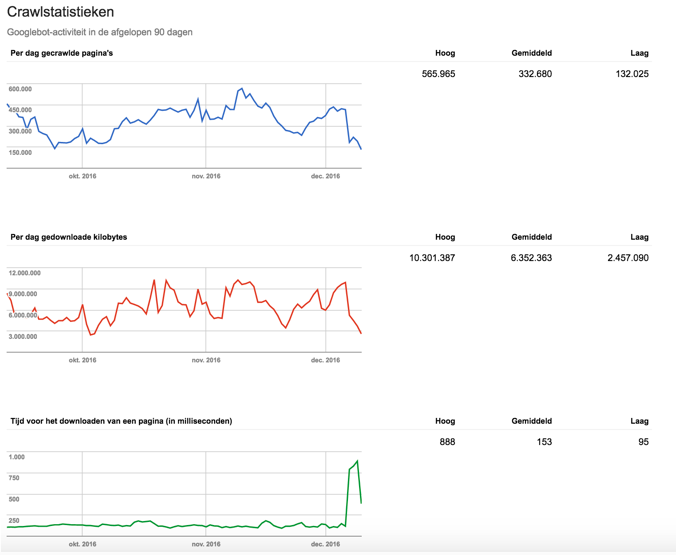
Eén van de elementen die vaak van grote invloed kan zijn op je crawl budget is de snelheid van de website. Googlebot besteedt tijd aan het renderen van een pagina, als je deze tijd terugbrengt dan zal Googlebot ook sneller de website crawlen. Op deze manier zullen pagina’s dus eerder bezocht worden. Hieronder laten we een voorbeeld zien waarbij de website snelheid omlaag ging (zie onderste grafiek) en wat dit voor invloed had op het aantal gecrawlde pagina’s per dag (zie bovenste grafiek).
Inkomende links
Inkomende links hebben ook een groot effect op het crawl budget van een website. Hoe meer externe links verwijzen naar je website, hoe meer links Googlebot dus kan volgen en hoe meer tijd er op je website wordt doorgebracht.
Hieronder zullen we vier factoren beschrijven hoe je je website kan optimaliseren op het gebied van crawl budget. Deze tips zullen ervoor zorgen dat Google meer aandacht besteedt aan pagina’s die veel waarde hebben om organisch verkeer binnen te halen. Aan de andere kant helpen deze tips ook om Googlebots geen aandacht meer te laten geven aan pagina’s die niet relevant zijn om geïndexeerd te worden.
-
Filters en duplicate content
Bij e-commercewebsites heb je veel te maken met product- of categoriefilters, die ervoor zorgen dat een URL er steeds anders uitziet. De verschillende combinaties van filters zorgen zo voor heel veel verschillende URL’s. Filters worden vaak achter een parameter geladen en deze zijn in sommige gevallen niet relevant om door Google gecrawld te worden en aandacht te krijgen.
Een aantal praktische voorbeelden hiervan zijn:
- Filter op prijs: Stel je voor, je hebt op elke mogelijke categorie een filter waarbij het mogelijk is om op een bepaalde prijsrange te filteren. Als het mogelijk is om te kiezen uit tien mogelijke prijsfilters, dan zorgt dit ervoor dat op elke mogelijke categorie met een unieke URL er tien URL’s bestaan die totaal niet relevant zijn om gecrawld te worden door Google. Voorbeeld URL’s:
- webshop.nl/rode-schoenen?price=10-20
- webshop.nl/blauwe-schoenen?price=50-70
- Zoekresultaten: Een veelvoorkomend probleem bij websites met een interne zoekfunctie is dat deze zoekopdrachten unieke URL’s genereren die niet worden uitgesloten van indexatie. Dit kan op termijn leiden tot een groot aantal aan URL’s waarvan je niet wilt dat deze geïndexeerd worden. Deze URL’s zouden daarnaast mogelijk kunnen conflicteren met de categoriepagina’s op de website. Voorbeeld URL’s:
- webshop.nl/zoeken?search=rode%schoenen
- webshop.nl/zoeken?search=blauwe%schoenen
Nu hoor ik je denken, deze twee simpele voorbeelden kunnen slechts enkele URL’s genereren. Bij één van onze klanten hebben we het crawl budget ook geoptimaliseerd, hieronder kun je zien hoe we dat gedaan hebben:
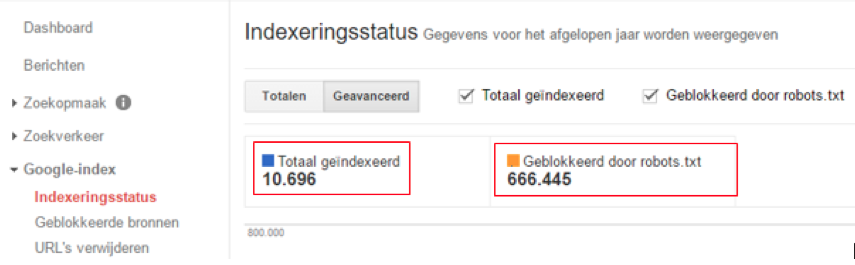
In dit voorbeeld werden er allerlei soorten categoriefilters en zoekfilters geïndexeerd door Google. Als deze pagina’s niet waren uitgesloten van de indexatie, dan zou Google mogelijk 666.445 URL’s crawlen die helemaal geen aandacht horen te krijgen. Door het uitsluiten van de filters zorg je ervoor dat de pagina’s die wel relevant zijn wel gecrawled worden. Dit kan zelfs bijdragen aan een hogere positie in Google, doordat Google vaker op deze (belangrijkere) pagina’s komt.
Het uitsluiten van filters kan op verschillende manieren. Als we de zoekfilters van het bovenstaande voorbeeld willen uitsluiten van de indexatie in Google, dan kunnen we de volgende regel toevoegen in de robots.txt :
- Disallow: ?search
Voor de techies onder ons; deze disallow regel zegt eigenlijk tegen Googlebot dat URL’s met het pad ?search in de URL niet gecrawld mogen worden. Dit lost alleen nog niet het probleem op met alle URL’s die in de zoekresultaten van Google zullen blijven. Daarom is de beste oplossing in dit geval om eerst een “noindex” regel toe te voegen en daarna een disallow. Daarnaast kun je ook een nofollow tag plaatsen op filter URL’s, dit is een alternatieve oplossing. Hiermee wordt aangegeven dat GoogleBot de URL niet mag volgen, zo wordt deze dus ook niet geïndexeerd.
-
Duplicate content
Een ander veelvoorkomend probleem is duplicate content, ofwel pagina’s met identiek dezelfde content op een andere URL. Er bestaan veel verschillende varianten van duplicate content, daarom zullen we een voorbeeld geven die we veel tegenkomen bij webshops.
Stel, je verkoopt een bepaalde type bril, deze bril is bereikbaar via verschillende categorieën met elk een eigen URL. Dan betekent dit dat identiek dezelfde content op twee of meer verschillende URL’s staat. Als voorbeeld:
- webshop.nl/heren-brillen/bril-type-x/
- webshop.nl/brillen/bril-type-x/
Als dit probleem zich voordoet bij bijvoorbeeld 1000 producten die elk op twee verschillende URL’s beschikbaar zijn, dan betekent dit dus dat Google onnodig twee keer zo lang nodig heeft om alle producten te crawlen. Vervolgens wordt dit dan ook nog als duplicaat gezien.
Om te checken of je te maken hebt met dezelfde producten op verschillende URL’s kun je de volgende zoekopdracht uitvoeren in Google:
- site:webshop.nl “Productnaam”
Als je vervolgens twee of meer dezelfde resultaten ziet, dan weet je genoeg.
-
Interne 404’s en redirects
Interne 404-pagina’s zijn een boosdoener voor elke website, dit zien we dan ook regelmatig terugkomen. Wanneer Google links op de website volgt en op een 404-pagina uitkomt, kan dit negatieve gevolgen hebben voor je crawl budget.
Interne 404’s zijn makkelijk terug te vinden via de Search Console onder het kopje “Crawlen → Crawlfouten → Niet gevonden”. Om dit probleem te verhelpen kun je de volgende twee dingen doen:
- De interne link aanpassen naar een werkende pagina (aan te raden)
- De URL 301 redirecten naar een werkende pagina
Nu hoor ik je denken “Een 301 redirect lost het probleem toch ook op?” Dat klopt, maar het zorgt wel voor interne redirects waardoor Googlebot meer tijd nodig heeft om op de gewenste URL te komen. Daarom raden we altijd aan interne links die met behulp van een 301 redirect naar de gewenste URL gaan, aan te passen naar de eindlocatie, zodat de redirect wordt vermeden.
Daarnaast kan er nog een groter probleem zijn, namelijk een redirect chain op de website. Dit is een loop van redirects op de website, ook wel een constante herhaling van redirects. Dit probleem zien we minder vaak terugkomen, maar het kan een groot effect op je crawl budget hebben. Hieronder zie je een praktisch voorbeeld waarbij je ziet dat de ene URL redirect naar de ander en andersom.

In dit voorbeeld wordt de Googlebot van de ene URL naar de andere gestuurd zonder dat er ook maar één werkende URL wordt gecrawld.
-
Analyseer server logs
Een vierde manier om het crawl budget op de website te analyseren is via een server log analyse. Met deze analyse kun je achterhalen of de juiste pagina’s op de website de juiste aandacht van zoekmachines krijgen.
Een server log analyse kun je uitvoeren met een tool als Screaming Frog. Deze analyse laat alle server logs zien, waarbij je de data van de user agent (bijvoorbeeld GoogleBots) die de URL heeft gecrawld ziet. Daarnaast kun je de statuscode, responstijd, aantal keer gecrawld en aantal gedownloade bytes terugvinden.
Een serverlog-analyse is vrij ingewikkeld om uit te voeren, maar het laat wel duidelijk zien hoe user agents (bots) de website crawlen en hoe vaak ze op welke pagina’s zijn geweest.
Conclusie
Met deze tips hopen we dat je ook kunt starten met het optimaliseren van het crawl budget voor je website. Deze tips zijn ook niet alleen handig om je crawl budget te verbeteren, maar optimalisaties zoals pagespeed en navigatie links kunnen ook de gebruikerservaring voor bezoekers verbeteren. Daarnaast zijn inkomende links ook buiten het crawl budget om een erg invloedrijke factor. Realiseer je hierbij dat hoe groter jouw website is, hoe belangrijk crawl budget voor je website is.
Deel dit bericht
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond
5 Reacties
jeroen - chalet.nl
Beste Jason,
Raad jij aan alle 404 pagina’s door te verwijzen met een 301 redirect?
Ik hoor graag van je,
Jeroen
Sjoerd Jochems
Zie vooral Filters en Zoeken
Jason van Alphen - Expand Online
Beste Jeroen,
Idealiter krijgen 404 pagina’s altijd een 301 redirect naar een nieuwe URL. Je wilt immers voorkomen dat 1. GoogleBot hier tijd aan spendeert 2. Bezoekers hier vanuit organische zoekresultaten op landen.
Tevens is het aan te raden om bij het maken van een 301 redirect de meest relevante nieuwe URL te kiezen. Als voorbeeld: Stel je verkoopt rode schoenen en een bepaalde rode schoen wordt niet meer verkocht. Dan is de meest logische redirect naar de bovenliggende categoriepagina, in dit geval “Rode schoenen”.
Mocht je een hoop 404 pagina’s tegenkomen in de Search Console welke een parameter bevatten zou je deze nog met een automatische regel kunnen afvangen (meest tijd efficiënt).
Ik hoop dat je vraag hiermee beantwoord is.
Groeten,
Jason van Alphen
Larissa
Hé Jason,
Bedankt voor dit duidelijke artikel. Ik begin nu echter toch een beetje te twijfelen. Wij hebben de vraag rondom crawl budget en onze grote hoeveelheid nutteloze productfilter URL’s bij een online marketingbureau neergelegd. Zij zeggen dat wij hier geen zorgen over hoeven te maken vanwege de canonieke URL’s waarmee wij naar de (hoofd)categorie verwijzen en dat Google deze URL’s goed kan onderscheiden. Nu blijft de vraagt: productfilter URL’s wel of niet uitsluiten in ons Robots.txt bestand?
Groeten,
Larissa
Sander - Euroholidays
Hoi Larissa, dan zou ik snel op zoek gaan naar een ander online marketing bureau ;-). Een canonical kan een zoekmachine pas zien wanneer de pagina gecrawld is, dus dit is wel gelijk zonde van je crawlbudget. Uitsluiten in robots.txt is eenvoudige optie (dit is voor zoekmachines een indicatie geen garantie). Ook kun je de interne links voorzien van een nofollow element. Succes!