Het headless Customer Data Platform: De voor- en nadelen op een rij
In navolging van het headless Content Management Systeem: het headless Customer Data Platform. Wat zijn de voor- en nadelen in vergelijking met bestaande tools en wanneer is een Headless CDP interessant?
Een term die je steeds vaker voorbij zult zien komen: het headless Customer Data Platform (CDP) of Data Management Platform (DMP). Een exacte definitie is er niet, maar gaat om een steeds populairder wordende oplossing: een data-warehouse in de cloud waar op allerlei niveaus inzichten en acties gecreëerd kunnen worden, mét de mogelijkheid om direct vanuit deze omgeving data te activeren in kanalen, platforms en tools. Dit alles zonder een stand-alone CDP-tool of –suite.
Headless?
De term headless is komen overwaaien uit de hoek van het contentmanagement, waar headless CMS-systemen enorm populair zijn. Het concept: het loskoppelen van de back-end (contentmanagement) en de front-end (website). Het CMS krijgt de rol van centrale contenthub. Via een API kan content gedeeld worden met alle mogelijke systemen, zoals websites maar bijvoorbeeld ook dynamisch samengestelde e-mails of apps. De front-end is dus niet meer verweven met het contentmanagementsysteem. Resultaat: content gecentraliseerd in één systeem en front-end-applicaties kunnen onafhankelijk doorontwikkeld worden, zonder beperkingen van het CMS.
Het headless CDP of DMP daarentegen is een centrale datahub waar op allerlei niveaus inzichten gecreëerd kunnen worden, maar ook gekoppeld worden aan kanalen, tools of platforms. Dat gebeurt direct vanuit de cloud, zonder dat daar een stand-alone CDP-tool voor nodig is. Er is echter geen centrale interface maar een aaneenschakeling van services en connectors binnen de cloudomgeving (bouwblokken).
Niet alleen klantdata
In dit artikel ligt de focus op klantdata (CDP) omdat de vergelijking met bestaande systemen dan wat makkelijk gemaakt kan worden. Echter, ‘CDP’ dekt de lading niet, want in een headless datamanagementsysteem hoeft het zeker niet alleen om klantdata te gaan. Denk aan:
- Het samenstellen van een centraal klantbeeld en doelgroepen (audiences).
- Het verrijken van productdata en inzicht in productprestaties.
- Creëren van modellen en voorspellingen zoals productaanbevelingen, purchase of churn predictions maar ook verkoopvoorspellingen, zowel in batch als realtime.
- Creëren van business rules of “triggers” voor vervolgacties.
- Sales– en engagement-rapportages en -notificaties op basis van verschillende bronnen (sales, website en/of kanalen).
Een datawarehouse ‘with benefits’
Veel organisaties hebben de afgelopen tijd geïnvesteerd in het opzetten van een data-warehouse in een van de cloudproviders zoals AWS, Azure of Google. Data kan uit verschillende bronnen binnengehaald en gekoppeld worden. Meestal is dit op basis van periodieke batches maar steeds vaker stroomt de data ook realtime naar binnen. Denk aan orders of clickstream-data vanuit de website / app.
Het werken met zo’n data-warehouse en de diensten daaromheen is de afgelopen jaren een stuk eenvoudiger geworden. De verschillende diensten binnen de cloud zijn relatief eenvoudig op elkaar te stapelen waardoor importeren, transformeren en analyseren van grote hoeveelheden data gemakkelijker is geworden. Vaardigheden die van belang zijn om met een dataomgeving te werken, zoals SQL, R en Python zijn bovendien ook steeds meer aanwezig binnen organisaties
Het activeren van deze data in kanalen en/of tools is de laatste stap die het data-warehouse en de diensten daaromheen tot een headless CDP of DMP maken. Het grote voordeel van zo’n aaneenschakeling van services: de flexibiliteit van het data-warehouse waar complexe combinaties en use cases gecreëerd kunnen worden, die vaak niet mogelijk zijn in drag-and-drop interfaces. Het betekent echter ook dat deze oplossing overlap heeft met bestaande stand-alone-systemen.
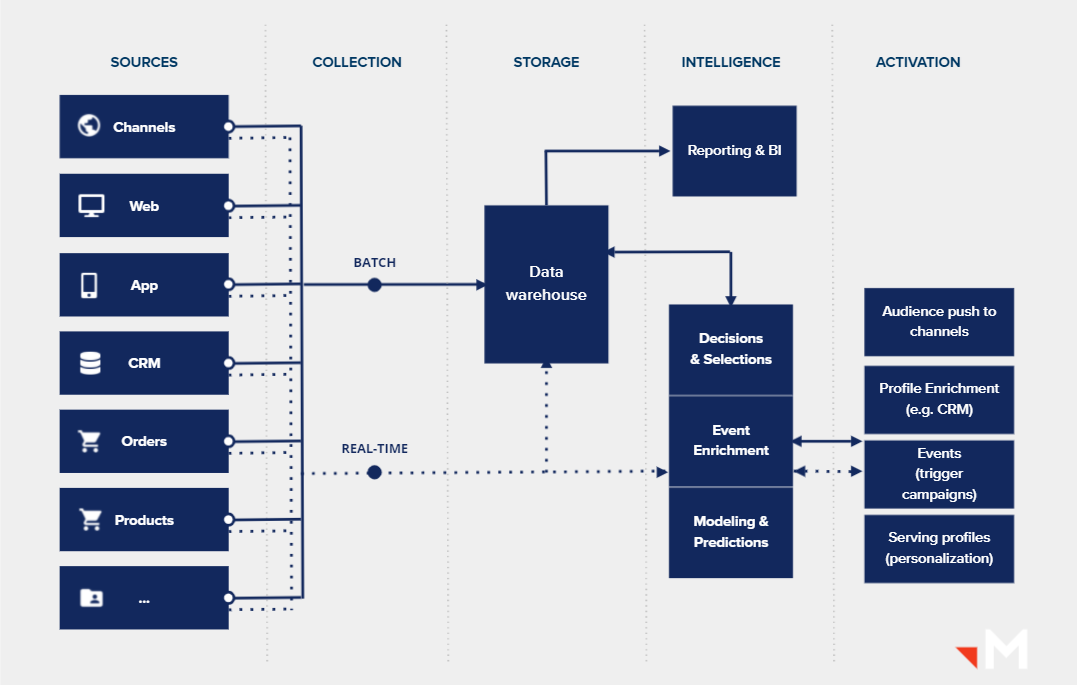
CDP-datastromen: overlap tussen CDP-tooling en functionaliteit binnen het data-warehouse
Headless CDP versus CDP-tooling: Overlap in functionaliteit
Inmiddels zijn er vele ‘smaken’ CDP’s. Qua functionaliteit kun je CDP’s niet over een kam scheren. Het ene systeem focust zich bijvoorbeeld meer op personalisatie en het andere op het creëren van inzichten, AI of een centraal klantbeeld. In de meeste gevallen is het echter wel zo dat deze systemen ook alle brondata willen verzamelen. Vaak moeten Javascript-trackers geïmplementeerd worden op de website en periodiek CSV’s geüpload worden om de online data aan te vullen met order- of CRM-data. In relatie tot stand-alone CDP-tooling kom ik daarom bij organisaties regelmatig de volgende zaken tegen:
- Het is gek dat alle databronnen die het data-warehouse instromen, nog een keer ontsloten moeten worden binnen een CDP-tool.
- Het moeten dupliceren van business rules zoals doelgroepselecties of een centraal klantbeeld binnen de CDP-tooling.
- Het ontsluiten van alle realtime online data kan tegenwoordig al via aanwezige tools zoals Google Analytics of Snowplow, dan wel de steeds populairder wordende server-side tag management-systemen.
Natuurlijk is dit afhankelijk van je specifieke situatie, maar in de meeste gevallen is er sprake van flink wat overlap. En de meeste CDP- en datamanagement-tools werken (nog) niet op zo’n manier samen dat ze kunnen meeliften op alles wat er al in je data-warehouse verzameld en berekend wordt.
De voordelen van stand-alone CDP’s
Natuurlijk hebben stand-alone CDP’s ook voordelen:
- Een user interface: een headless systeem heeft geen geïntegreerde user interface waar instellingen gemakkelijk aangepast kunnen worden of inzicht gegeven kan worden in alle processen. Het is zeker mogelijk om inzicht te krijgen in de processen van een headless systeem, maar die inzichten moeten zelf gecreëerd worden.
- Realtime decision engine / flow-builder: het maken van beslissingen op basis van realtime datastromen (bijvoorbeeld web- of appdata). Het creëren van zo’n realtime decision engine in de cloud is ook mogelijk, maar is veel complexer dan het bij elkaar klikken van rules in een interface.
- In realtime en in hoog volume aan kunnen bieden van (klant)profielen ten behoeve van (website- of app-)personalisatie. Zo’n systeem creëren in een cloudomgeving heeft wat voeten in de aarde.
- Connectiviteit met kanalen en tools wordt door het platform onderhouden. In een headless CDP moet dit zelf opgezet worden (vaak via API koppelingen), al zijn er tegenwoordig meerdere (open-source) oplossingen en connectors beschikbaar, zoals Google Tentacles.
Nieuw: de hybride oplossing
Een interessante trend is dat zowel bestaande als nieuwe CDP-(achtige) tools steeds meer bewegen naar een hybride oplossing. Dat wil zeggen, de systemen kunnen steeds beter samenwerken met bestaande cloudomgevingen / data-warehouses. Uiteindelijk zou dit er voor moeten zorgen dat je zelf in de cloud de realtime en batch dataverzameling en (een deel van) de intelligence kunt regelen. Een tool regelt dan bijvoorbeeld de user interface, het maken van realtime beslissingen en/of de data-activatie (connectors).
Echter, in de praktijk gaat vaak nog enkel om een simpele import of export naar je cloudomgeving. Met een headless CDP sorteer je in ieder geval voor op deze ontwikkeling.
Wanneer is een headless CDP interessant?
Een Headless CDP kan absoluut interessant zijn indien je:
- als organisatie bezig bent met een data-warehouse in de cloud of van plan bent dit in de nabije toekomst op te tuigen;
- zonder het aanschaffen en implementeren van een vaak prijzige CDP-tools bijvoorbeeld doelgroepen, triggers of andere data direct vanuit het data-warehouse wilt delen met kanalen of (externe) platforms;
- geavanceerde use cases op basis van veel verschillende bronnen en combinaties wilt realiseren (in stand-alone tools is het niet bij elkaar te klikken en de logica in een data-warehouse is vaak al aanwezig);
- data en business rules hoeven niet gedupliceerd te worden in verschillende omgevingen;
- ook andere soorten data wilt ontsluiten en activeren, zoals productdata of geavanceerde inzichten in sales of engagement.
Met behulp van verschillende clouddiensten is het mogelijk om data en tools relatief eenvoudig met elkaar te verbinden. Houd er wel rekening mee dat er bepaalde skills aanwezig moeten zijn in het team dat dagelijks gaat werken met het headless CDP. Denk aan data-engineers, technisch onderlegde marketeers en analisten. Dit is met name belangrijk naarmate de use cases complexer worden. Waarschijnlijk zijn deze skills al intern of extern aanwezig, gezien de wens om überhaupt een data-warehouse op te zetten.
Werk concrete ‘use cases’ uit
Inzicht en gebruiksgemak zijn zeker voordelen van een stand-alone CDP, al is het in de praktijk zo dat de belofte dat iedere marketeer met een CDP kan werken vaak niet waargemaakt wordt. Of dat aan de marketeer of aan de tool ligt zal per situatie en persoon verschillen. Feit is wel dat in de praktijk de meer technische marketeers en/of data-engineers de hoofdgebruikers zijn van dergelijke systemen.
Een open deur, maar bij de keuze tussen een headless of een stand-alone CDP is het enorm belangrijk om concrete use cases uit te werken en te bepalen wie er met zo’n systeem gaat werken. “Eenvoudig bij elkaar kunnen klikken van audiences en delen met kanalen” is geen concrete use case. Je kunt een klant of lead niet 10 uitingen tegelijk laten zien. Het creëren van 100 doelgroepen, waarvan dezelfde klant/gebruiker in de praktijk in 70 van deze 100 doelgroepen zit, en ook 70 keer met een andere boodschap getarget wordt, werkt niet.
De beste tip die ik daarom kan geven is om dit soort vraagstukken verder uit te werken met meerdere disciplines binnen je organisatie voordat je een keuze gaat maken.
Over de auteur: Krisjan Oldekamp is Marketing technology lead bij Merkle Nederland.
Op de hoogte blijven van het laatste nieuws binnen je vakgebied? Volg Emerce dan ook op social: LinkedIn, Twitter en F
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond