Hyperautomation: volledig automatische documentverwerking (2/5)
Automatisch documenten digitaliseren en sorteren? Informatie uit documenten extraheren en die volledig digitaal verder verwerken en gebruiken? Facturen invoeren en ordenen? Automatische documentverwerking is een van de meest concreet bruikbare toepassingen van hyperautomation.
Meer dan 80% van de data in bedrijven is ongestructureerde content. Denk aan facturen, e-mails, gescande pdf-documenten, foto’s of handgeschreven documenten. Ongestructureerde data verschilt van gestructureerde data doordat het een oordeel of een vorm van besluitvorming vereist bij de verwerking. Lange tijd werden deze documenten en afbeeldingen handmatig ingevoerd om ze verder te gebruiken in bedrijfsprocessen. Het handmatig verwerken van deze documenten leidt echter vaak tot problemen: hogere werkdruk, lange doorlooptijden, hoge kosten en foutenpercentages. Deze factoren zorgen ervoor dat bedrijven zoeken naar oplossingen op het gebied van hyperautomation in combinatie met kunstmatige intelligentie. Deze technieken bieden vele automatiseringsmogelijkheden.
Zien en lezen met computer vision
Bij de mens ontstaat zicht uit een samenspel tussen de ogen en de hersenen. Met nieuw opkomende technologieën wordt het proces van ‘zien’ en het verder gebruiken van informatie nu ook mogelijk voor computers. Hierbij gebruikt de computer een camera of scanner om objecten, afbeeldingen en tekst te kunnen zien en lezen. Met behulp van computer vision-technologie kunnen documenten – zoals getypte en handgeschreven teksten op papier – worden omgezet in bruikbare (digitaal leesbare) tekst. Bij computer vision komen verschillende technologieën samen om ongestructureerde documenten te verwerken.
Onder computer vision vallen verschillende technologieën, meer in het bijzonder:
- Optical Character Recognition (OCR)
- Intelligent Character Recognition (ICR)
- Machine Learning
- Deep Learning
OCR is een technologie die wordt gebruikt wanneer een gescand of gefotografeerd document moet worden omgezet in digitale tekst. OCR werkt op basis van patroonherkenning. De tekst die moet worden gelezen, wordt eerst gescand en herkend als afbeelding. Vervolgens destilleert OCR-software letters, cijfers en leestekens uit het plaatje op pixelniveau waaruit een elektronisch stuk tekst ontstaat.
Waar OCR tekst uit afbeeldingen extraheert en deze in een elektronisch bruikbaar formaat omzet, voegt ICR kunstmatige intelligentie (AI) toe aan de OCR-engine en verbreedt hiermee het scala aan intelligent document-processing-oplossingen. ICR kan onder andere het document lezen, het document classificeren, de relevante gegevens uit het document halen, de gegevens valideren en de gegevens in een gestructureerde vorm aanleveren voor verdere verwerking.
Machine Learning (ML)-technologie is het hulpmiddel dat wordt gebruikt om de computer verschillende karaters van het gescande document te laten herkennen op basis van een training dataset. Te denken valt aan het aantal tekens en talen dat een computer kan herkennen. Met speciale Deep Learning (DL)-modellen is onder andere beeldherkenning, objectdetectie en beeldreconstructie mogelijk. DL is een hulpmiddel dat wordt gebruikt om een gescand document of een afbeelding te identificeren en te classificeren en ligt aan vele computer vision-technologieen ten grondslag.
Om ongestructureerde documenten te verwerken zijn dus verschillende stappen nodig. Het gehele proces is op de volgende manier schematisch voor te stellen:
Een praktijkvoorbeeld
- Stap 1: Identificeren en bijsnijden
Het isoleren van het document wordt gedaan door de toepassing van basic algoritmes. Deze gaan op zoek naar de randen van het document, isoleren het gewenste gedeelte van het document en snijden het bij.



- Stap 2: Classificeren. De weergegeven identiteit is een specimen document
Algoritmische computermodellen op basis van ML en DL kunnen bepaalde eigenschappen van het document herkennen en een match vormen met de reeds beschikbare data in de database. Op basis van bijvoorbeeld nationaliteit (tekst in geel op in de afbeelding hieronder) kan dit document worden geclassificeerd.
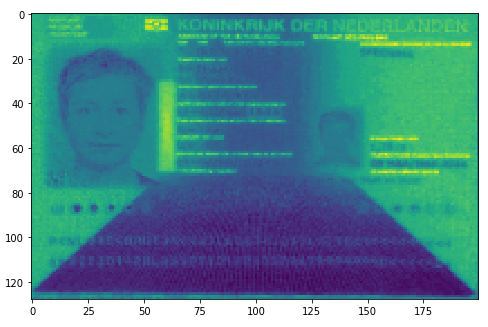
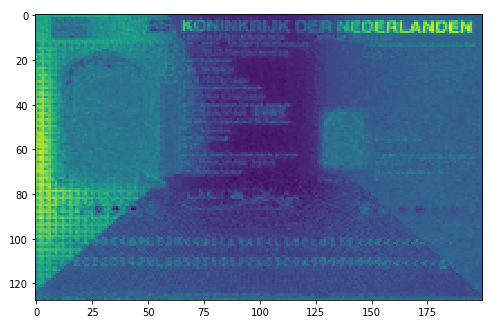
- Stap 3: Voorbewerken.
Voor het bewerken van het beeld zijn diverse technieken beschikbaar die het mogelijk maken om de tekst beter uit het beeld als geheel te kunnen extraheren. Voorbeelden daarvan zij Adaptive Thresholding en het veranderen en analyseren van kleurpatronen (zie de afbeeldingen hieronder).






- Stap 4: Tekstextractie
Deze tekst kan vervolgens met behulp van diverse technologieën worden geëxtraheerd en gebruikt voor verdere (geautomatiseerde) besluitvorming en verwerking.


De drie beeldverwerkingstappen hierboven leiden tot de tekstextractie hieronder

- Stap 5: Vervolgstappen
Nadat de tekst is geëxtraheerd kan de verkregen extractie op diverse manieren als input fungeren voor verdere stappen. Zoals verder uitgelegd in deel 4 van deze serie kan een technologie als computer vision worden aangevuld met Robotic Process Automation (RPA). Te denken valt hierbij aan een typisch financieel proces: crediteuren, debiteuren. Facturen met verschillende lay-outs kunnen worden uitgelezen door ICR-technologie (factuurnummer, bedrijfsnaam, etc.) en de juiste match kan zo worden gemaakt. Vervolgens kan een RPA-oplossing worden ingezet om deze uitgelezen waardes door te voeren in de interne systemen.
Deze voorbeelden laten zien hoe de combinatie van verschillende technologieën (hyperautomation) de mogelijkheid biedt om een proces van A tot Z te automatiseren. Het is daardoor toepasbaar in vele situaties. In de volgende aflevering van deze serie wordt dieper ingegaan op de mogelijkheden die hyperautomation en conversational AI creëren om een stap verder te zetten in de richting van een digitale strategie.
Dit is deel 2 uit een serie van 5.
- Deel 1 is een introductie tot hyperautomation
De kracht van de inzet van Artificial Intelligence zit in het verwerkbaar maken van ongestructureerde data, zoals beelden. - Deel 3 gaat in op Conversational AI
Wil je je klant direct betrekken in het automatiseren van jouw interne processen? Dan kun je het contact met die klant ook automatiseren door bijvoorbeeld de inzet van Conversational AI. - Deel 4 gaat in op Algorithmic Process Automation
Hier gaat het over het verbeterd voorspellen van de toekomstige vraag naar producten door de inzet van Algorithmic Process Automation en de samenwerking met RPA. - Deel 5 gaat in op het houden van controle
Moet je als organisatie het volledige proces wel wíllen automatiseren, zelfs als het kan? Of wil je juist bepaalde beslissingen laten nemen door een mens? Het slot gaat in op het houden van controle bij de inzet van Hyperautomation.
Over de auteurs: Mignon Rijnja en Tunna van Julsingha zijn beide Consultant Hyperautomation bij Capgemini Invent. Deze blog is mede mogelijk gemaakt door en met dank aan Jorrit Bootsma & Killian Toelge, technische experts bij Capgemini.
De weergegeven identiteit is een specimen document
Op de hoogte blijven van het laatste nieuws binnen je vakgebied? Volg Emerce dan ook op social: LinkedIn, Twitter en F
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond