Een introductie tot machine learning (I)
Machine Learning, AI en deep learning lijken in veel opzichten losstaande zaken, maar zijn onlosmakelijk met elkaar verbonden. Het is namelijk een subset van elkaar. In het eerste deel van dit vijfluik wordt aan de hand van voorbeelden uitgelegd wat Machine learning, AI en deep learning inhouden.
Laten we beginnen bij de basis: wat zijn machine learning, AI en deep Learning en hoe worden deze in de praktijk gebruikt? Als je dit artikel hebt gelezen, heb je de benodigde voorkennis om het volgende deel in de reeks te begrijpen.
Machine learning, AI, deep learning is een familie
Machine learning, deep learning en AI zijn familie van elkaar. De drie onderwerpen hebben met elkaar te maken. Ze zijn eigenlijk afhankelijk van elkaar. De onderwerpen worden van elkaar besproken, zodat je een beter beeld hebt over deze termen.
Machine learning
Met machine learning kan je door middel van big data een algoritme ontwikkelen wat voorspellingen kan doen. Machine learning is dus afhankelijk van data, en met deze data kan je een bepaalde output voorspellen van een dataset. Je moet echter wel eenmalig aangeven wat goed of fout is binnen de data. Het beste is dit uit te leggen middels een praktijkvoorbeeld.
Voor een Nederlandse fashion website wil een klant nieuwe producten automatisch classificeren in een categorie op de website. Op deze manier zijn er minder FTE’s nodig om handmatig producten toe te wijzen aan een categorie. Een flinke besparing voor de organisatie dus. Dit kan door een algoritme gedaan worden. Wij hadden de dataset van 40GB ingeladen; big data dus. Nu moet de data getraind worden. Het trainen van data betekent dat de algoritme moet leren in welke categorie een product hoort. In dit geval moet het algoritme weten dat skinny jeans onder Jeans->Skinny jeans valt. Toen de data was getraind, was de machine learning algoritme klaar. De meest voorkomende fashionproducten worden nu automatisch geclassificeerd in de juiste categorie.
De klant had vervolgens een nieuwe leverancier die zijn productnamen in het Engels aanlevert. Nu kan het algoritme niet herkennen of de Engelse producten onder de juiste categorie vallen en moet de data opnieuw getraind worden voor Engelse producten. Dit is precies wat machine learning is. Het algoritme heeft instructies nodig en kan nieuwe patronen niet herkennen. Dat brengt ons bij de mogelijke oplossing; deep learning.
Deep learning
Deep learning lost het probleem van machine learning op. Bij machine learning moet je een algoritme instructies geven om een item te classificeren in een categorie. In het bovenstaand voorbeeld bij de Fashion website zag je dat de machine learning algoritme niet om kon gaan met nieuwe (Engelse) data. deep learning kan dit echter wel door bepaalde patronen te herkennen. Als we ons algoritme veranderen naar een deep learning algoritme, dan is de algoritme slim genoeg om te weten dat een “dress” en een “jurk” precies hetzelfde is.
Artificial intelligence
AI is simpelweg dat de computer zelfstandig intelligente beslissingen kan nemen. Met machine learning en deep learning heb je deels AI maar niet helemaal. Het is wetenschappers nog niet gelukt om dezelfde capaciteiten als het menselijke brein in een algoritme te implementeren. De algoritmes zijn gebaseerd op calculus, statistiek en lineaire algebra. Je hoort vaak dat deep learning en machine learning AI zijn, maar dat is eigenlijk niet waar. Voor onze fashion website is een deep learning model het beste om categorieën te classificeren, omdat we nog niet het menselijk brein digitaal kunnen maken.
Hoe ontwikkel je een machine learning algoritme
Een algoritme wordt in de praktijk ontwikkeld met Python. Het is aangeraden om machine learning applicaties te schrijven in Python omdat de libraries voor machine learning op deze taal gebaseerd is. Zoals de meeste mensen denken hoef je de algoritmes niet zelf te schrijven. Binnen Python is er een library dat sci kit learn heet. Hier kan je diverse algoritmes aanroepen . Belangrijk is wel om te weten welk algoritme je moet gebruiken.
Visualiseren van data
Als je aan de slag gaat met machine learning kom je er snel achter dat je data moet visualiseren in een assenstelsel. Op deze manier weet je wat de correlaties zijn tussen bepaalde data eenheden. Het visualiseren van data kan met Python gedaan worden door middel van Jupyter Notebook. Dit is een tool om data te visualiseren. Als je de data gevisualiseerd hebt weet je ongeveer welk algoritme je kan gebruiken. In het onderstaande voorbeeld is data geplot in een assenstelsel:
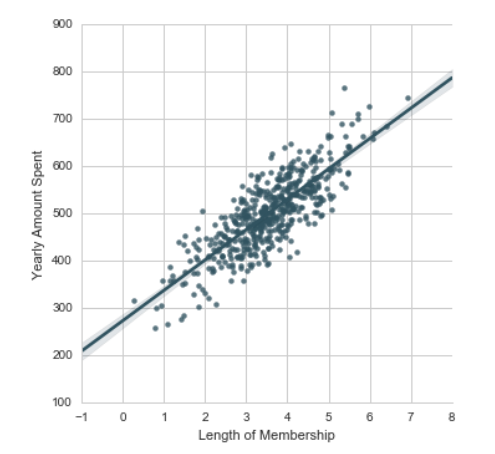
Je ziet dat de data een correlatie met elkaar heeft. Op basis hiervan kun je een lineair regressie algoritme gebruiken om voorspellingen te doen. Als nu iemand vijf jaar een member is, dan kun je erachter komen hoeveel hij gemiddeld uitgeeft.
Toekomstmuziek?
Hiermee zijn de verschillen besproken tussen machine learning, deep learning en AI. Je hebt gelezen dat deze onderwerpen aan elkaar gerelateerd zijn. AI is nog toekomstmuziek aangezien wetenschappers druk bezig zijn om het menselijk brein te digitaliseren. In praktijk wordt er gebruik gemaakt van deep learning, denk aan zelfrijdende auto’s. Het hangt van jezelf af of je dit interpreteert als AI of deep learning.
In het volgende artikel wordt dieper ingegaan op de algoritmes en volgen lineaire regressie en classificatieproblemen. Vervolgens zullen hier ook een aantal praktijkvoorbeelden volgen over hoe dit geïmplementeerd kan worden.
Over de auteur: Erwin Nandpersad is CEO bij Ermmedia.nl.
Deel dit bericht
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond
1 Reactie
Cees Bakker - Koppert Biological Systems
Een helder verhaal Erwin !! In veel artikelen worden de begrippen AI en ML door elkaar gebruikt of krijgen dezelfde uitleg. Hier geef je ieder begrip een juiste plek.