De optimale inrichting van data voor een centraal klantbeeld
Het doel van het hebben van een centraal klantbeeld is dat je de klant op het juiste moment zo goed mogelijk wil bedienen met relevante producten of diensten voor sales of service. Hiervoor is het van belang dat je over voldoende data beschikt en dat deze op een een goede, structurele manier is ingericht binnen je organisatie.
In dit tweede deel uit de artikelenserie van de DDMA Commissie Data, Decisions & Engagement laten we zien hoe je dat doet aan de hand van zes onderdelen: strategie, architectuur, datamodel, beschikbaarheid van bronnen, data-integratie en data governance.
Data is overal en groeit exponentieel
Grotere bedrijven gebruiken tientallen applicaties, die vanuit hun functie data genereren. Daarnaast gebruiken marketeers gemiddeld tot wel acht applicaties om een campagne uit te voeren. Als de ‘waarheid’ van data en informatie over de klantreis over meerdere applicaties, zoals webshop, email-tool en klantenservices, verspreid en gefragmenteerd is opgeslagen, is het onmogelijk om een centraal klantbeeld te realiseren. Het toepassen van diverse analyses en modellen heeft dan ook geen zin. Voor je het weet besteed je uren aan het uitzoeken waar de verschillen vandaan komen.
De zes bouwstenen om verspreide data structureel in te richten
Om verspreide data bij elkaar te brengen heb je een datamodel nodig, als onderdeel van de informatie-architectuur, waarin de onderlinge relaties zijn vastgelegd. Daarnaast sla je de data gecentraliseerd op in bijvoorbeeld een datawarehouse of datalake. Een Customer Data Platform (CDP) is meestal een subset van de data die relevant is voor marketing. Er zijn tegenwoordig vele varianten. Dit klinkt groots en omvangrijk, maar dat is simpelweg de beste manier om verspreide data aan te pakken. We laten je daarom zien hoe je data structureel inricht aan de hand van zes bouwblokken: datastrategie, architectuur, datamodel, beschikbaarheid van databronnen, integratie van data en data governance.
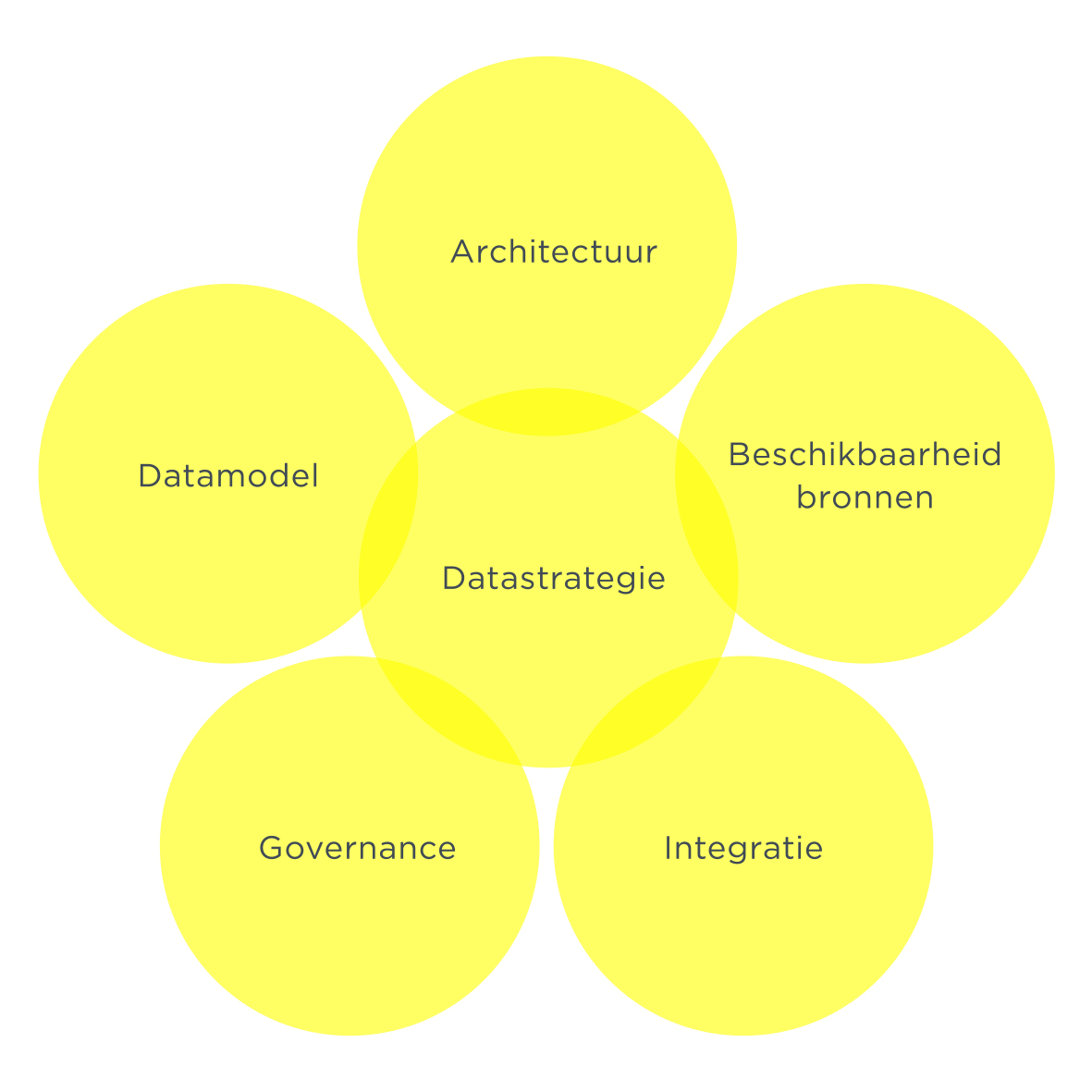
1. Datastrategie
Een datastrategie bestaat uit de volgende onderdelen:
- Organisatiedoelstellingen
- Datadoelstellingen
- Datawensen en -eisen
In het eerste artikel van deze serie ‘Zo realiseer je een centraal klantbeeld als fundament voor klantgericht communiceren’ zijn deze onderdelen concreet beschreven.
2. Architectuur
Een goede architectuur als basis voor een betrouwbaar datamodel bestaat uit 3 essentiële elementen: een feit-gerichte modelleringsmethode, een duidelijke informatiearchitectuur en een goede data-architectuur.
Een feit-gerichte (fact oriented) modelleringsmethode zorgt ervoor dat de interpretatie van de datatechniek door de business juist is. IT en de business maken een model met concrete voorbeelden, zodat deze door een eindgebruiker (bijvoorbeeld een marketeer) gevalideerd kan worden. Een belangrijk doel hiervan is om in een zo vroeg mogelijk stadium de verwachtingen naar elkaar uit te spreken en ervoor te zorgen dat je dezelfde taal spreekt en er geen fouten ontstaan in interpretatie van bijvoorbeeld rapportages .
Een goede informatiearchitectuur (IA) helpt om de vindbaarheid van informatie te verbeteren, om informatie makkelijk te hergebruiken, aan te bieden aan een relevante doelgroep en om meer grip te krijgen op informatie.
De data-architectuur is onderdeel van de enterprise-architectuur en is gerelateerd aan de informatie- en de applicatie-architectuur. Het biedt een overzicht van de beschikbare data en de relaties: databases, datamodel, datadefinities en datastromen.
Een enterprise-architectuur bestaat uit:
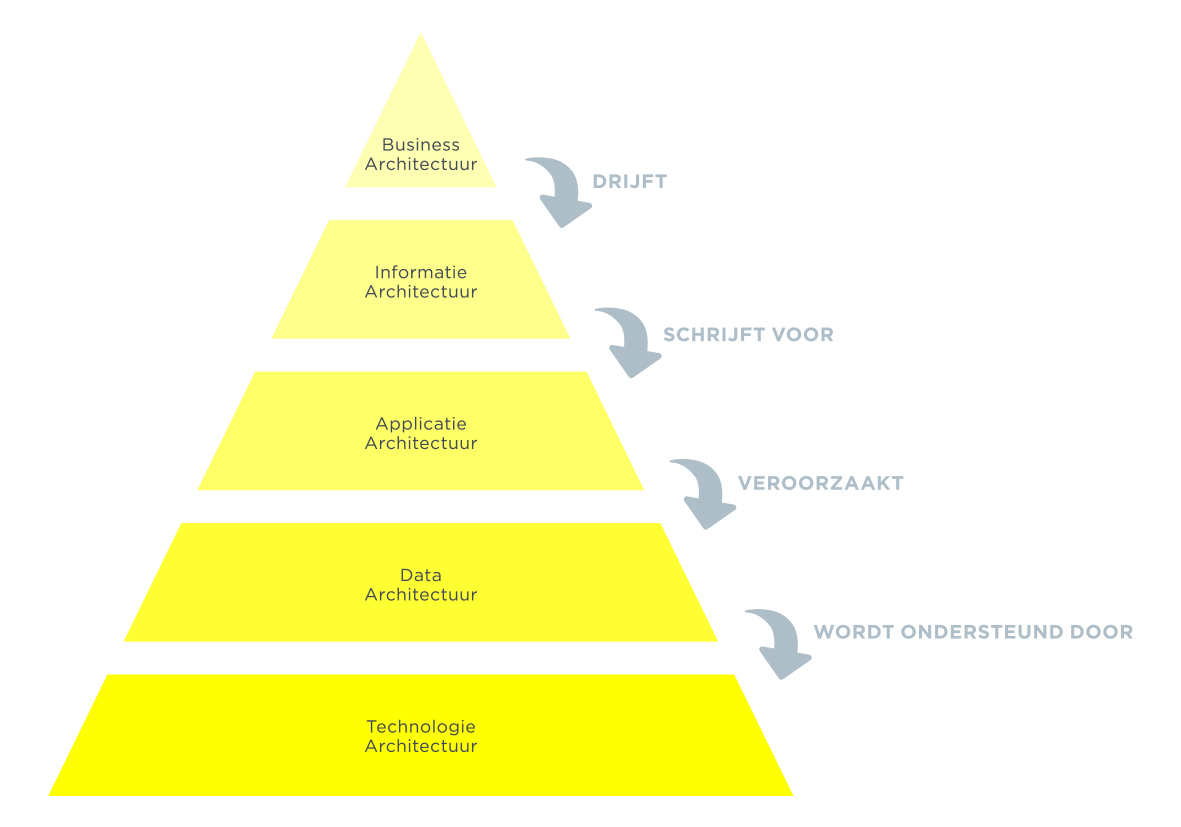
Schakel een informatiearchitect in om je te begeleiden met het opstellen van een informatiearchitectuur en een datamodel. Op basis hiervan kunnen services gebouwd worden zoals een Customer Data Platform om data te integreren en op te slaan.
3. Datamodel
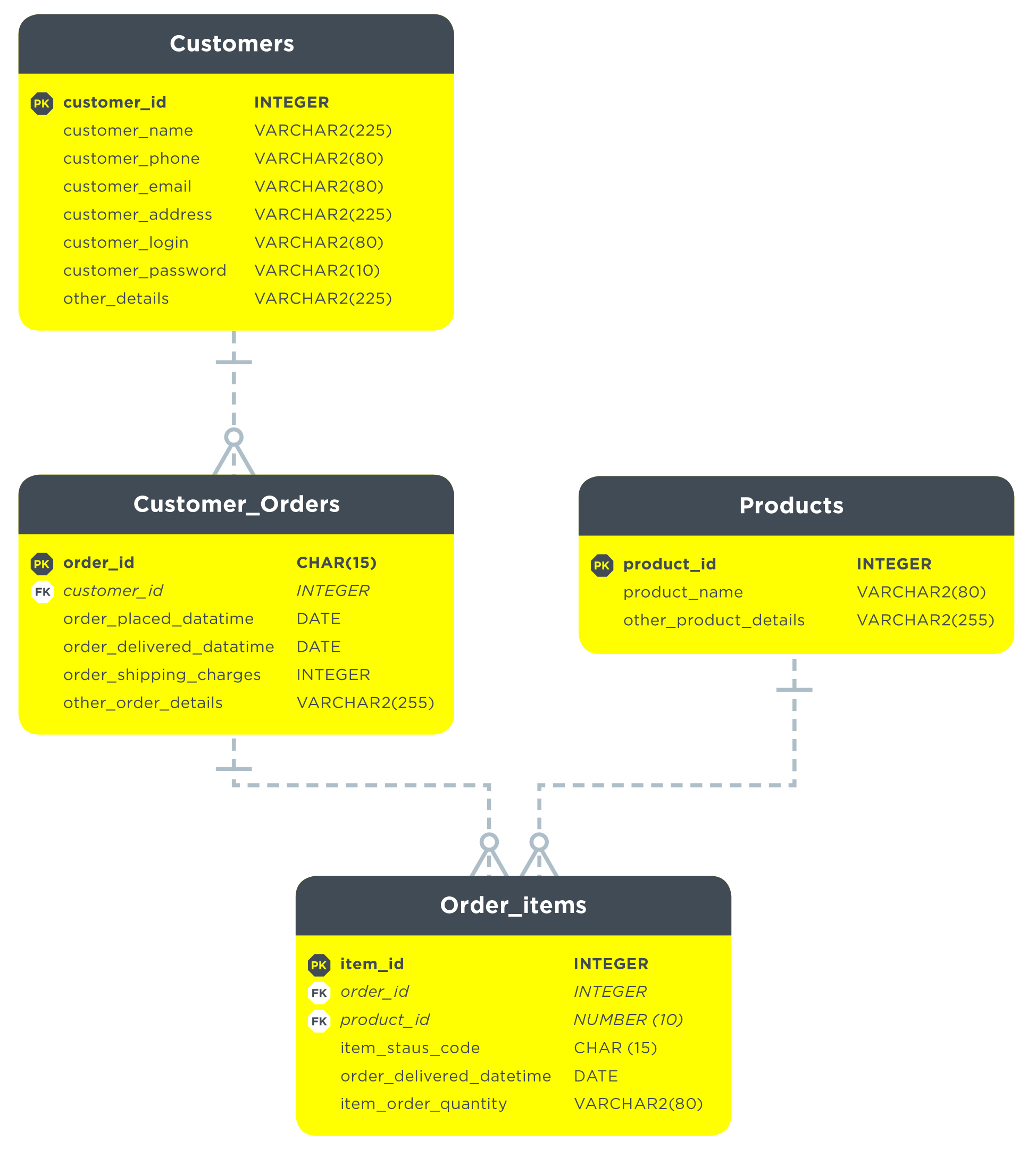
Een datamodel geeft weer hoe data op een vaste manier is gestructureerd. Je kunt hierbij het beste de ruwe data vanuit de bron opslaan in een eigen model. Zo heb je vanuit je eigen datawarehouse of -platform altijd toegang tot alle data en voorkom je dat je telkens afhankelijk bent van de aanlevering van nieuwe data. Vanaf dit punt kun je alle gegevens samenbrengen in een generiek model waarmee alle data vanuit alle bronnen op dezelfde manier wordt opgeslagen. Omdat data afkomstig is van verschillende bronnen kan het zijn dat data eerst bewerkt moet worden voordat een model het kan gebruiken. Dit proces heet datatransformatie en wordt gedaan door een data engineer.
In het datamodel leggen data engineers verschillende entiteiten, bijvoorbeeld “klanten”, “bestellingen” of “producten”, en hun onderlinge relaties vast. Deze entiteiten bevatten op zichzelf weer velden die iets vertellen over de entiteit. In het geval van “klanten” kan dit “naam” of “telefoonnummer” zijn. In het model worden ook de relaties tussen de entiteiten vastgelegd. De entiteit “klanten” wordt gelinkt aan de entiteit “bestelling” volgens specifieke regels. Zo kan bijvoorbeeld een “klant” meerdere bestellingen hebben, maar een bestelling niet meerdere “klanten”. Ook wordt daarin weergegeven dat bijvoorbeeld een klant meerdere orders kan hebben en een order niet meerdere klanten.
Dit is een voorbeeld van een datamodel waarin de onderlinge relaties van gegevens samen worden gebracht:
4. Beschikbaarheid van databronnen
Data kan bestaan uit talloze types van gegevens. De meest voor de handliggende zijn demografische gegevens (naam, adres, geboortedatum), verkochte producten of diensten en openstaande betalingen van bestellingen. Daarnaast kan data ook bestaan uit gegevens die iets zeggen over het gedrag van de klant – denk aan het lezen van e-mails, klikgedrag op websites en fysiek bezoek aan filialen. De meest populaire typen data van een klant zijn:
Klantattributen: leeftijd, geslacht, verjaardag, datum van eerste aankoop, segmentatiegegevens, klantvoorspellingen, toegepaste persona’s
Data over gedrag: websitebezoek, acties op website of in een app, clicks op advertenties, bezoek aan een winkel, social media-activiteit.
Transactionele data: aankoopgeschiedenis, afgenomen diensten, retouren, kassagegevens
Campagnedata: bereik, impressies, opens, clicks, engagement, conversie.
Klantrelatiegeschiedenis: data afkomstig van interacties met klantenservice, NPS-scores, data van chatbots, loyaliteit, beoordelingen, Customer Lifetime Value, churn-scores, etc.
Een voorbeeld van hoe PON haar centrale klantbeeld heeft ingericht:

Vaak is er binnen het bedrijf al een deel van deze data in bronnen en systemen aanwezig en is het een taak om hier een centraal beeld van te maken. Als organisatie is het de kunst om in te schatten welke typen data interessant zijn voor je klantbeeld. Als je nog geen idee hebt over je klantbeeld adviseren wij je klein te beginnen: inventariseer vanuit je use case(s) welke data nodig is en verzamel alleen die data. Zo kun je analyseren op welke gebieden je nog data mist. Of wellicht is er wel data, maar is dit alleen bruikbaar voor inzicht in je gehele klantenbase en niet 1-op-1 toe te kennen aan een klant. Door het aanpassen van processen en het zorgen voor slimme koppelingspunten breng je daar verandering in.
Een best practice is om eerst je customer en business journey in hoofdlijnen in kaart te brengen – zie ook artikel 1 uit deze serie. Voeg aan elk kanaal in dit journey-overzicht de datapunten per kanaal toe. Dit kan helpen om meer overzicht aan de dataverzameling voor het klantbeeld aan te brengen. Zeker in het begin kan het ongebreideld verzamelen van data zonder doel tot een overload aan data leiden. Door dit te koppelen aan een journey, maak je inzichtelijk aan welk doel data bijdraagt en kun je je werkzaamheden prioriteren.
5. Integratie van de data
De in het vorige punt genoemde data wordt vaak verzameld door verschillende applicaties die niet of niet volledig zijn geïntegreerd. Juist door data samen te brengen in een centrale database (zoals Big Query van Google Cloud Platform) of marketingplatform (zoals Salesforce of Adobe) maak je het mogelijk de data met elkaar in verband te brengen. Daarbij moet je goed kijken hoe je data van bronnen gaat onttrekken: kun je de data automatisch exporteren, duw (push) je de data naar het centrale systeem of haal (pull) je het binnen? Kan dit real-time, zodat je meteen een actie kan ondernemen door een trigger, of zit je vast aan batches?
Gegevens die uit verschillende bronnen komen, zijn meestal niet gelijkvormig. De ene databron heeft een veld ‘land’, de andere noemt het veld ‘country’. En ook de inhoud van deze dimensies kan verschillen als ‘NLD’, ‘Nederland’, ‘The Netherlands’, etc.. Voor beide is het nodig een eenduidige vorm te kiezen als standaard. Sommige platformen, zoals Google met Cloud Data Prep, hebben deze mogelijkheden tot datapreparatie ingebouwd om zonder kennis van code aan de slag te gaan. Heb je niet de beschikking over zo’n platform, dan moet je de data eerst consolideren in een datawarehouse. Hierbij kun je de keuze maken voor een Extract-Transform-Load-proces (ETL – transformatie in de datapipelines naar het datawarehouse) of Extract-Load-Transformproces (ELT – transformatie in het datawarehouse). Zie het voorbeeld van Google Cloud Data Fusion.
Een volgende stap om een klantbeeld samen te stellen is de data uit de verschillende bronnen unificeren naar een golden record. Hierbij worden verschillende bronnen gecombineerd om tot een zo actueel en compleet beeld van de klant te komen. Je kunt werken met businessregels, zoals bronnen-hiërarchie, waarbij je stelt dat een klantgegeven uit de ene bron betrouwbaarder is dan hetzelfde gegeven uit een andere bron. Met een golden record minimaliseer je de kans op dubbele klantrecords. Dit kun je realiseren door een goed match & merge-proces in te richten.
Typ- en spellingsfouten, verhuizingen, nieuwe telefoonnummers en wisselende e-mailadressen kunnen het lastig maken de data van een klant sluitend bij elkaar te brengen. Dit proces van data stitching vindt continu plaats, omdat profielen die op een eerder tijdstip nog gescheiden leken, in een later stadium door meer ontsloten data toch toegekend kunnen worden aan eenzelfde klant.
6. Data governance
Het belang van data governance wordt nog wel eens over het hoofd gezien. Het gevolg is dat de datakwaliteit met de tijd verslechtert, waardoor fouten worden gemaakt bij personalisatie en er meer tijd nodig is voor herstelacties. Data governance betekent kort gezegd de maatregelen om ‘in control’ te komen van data- en informatiestromen. Op het moment dat je in control bent, ben je immers in staat om het bestaande te verbeteren. Data governance bestaat uit het duidelijk(er) vastleggen van processen en regels omtrent het controleren en opschonen van data en het monitoren van bronnen, connectors en dataflows. Ook security en privacy zijn onderdeel van data governance.
Pragmatisch starten
Nu je alle databouwstenen kent, heb je een totaaloverzicht van hoe je een centraal klantbeeld inricht. Dit is een omvangrijk proces, dus we raden je aan pragmatisch te starten met onderstaande stappen:
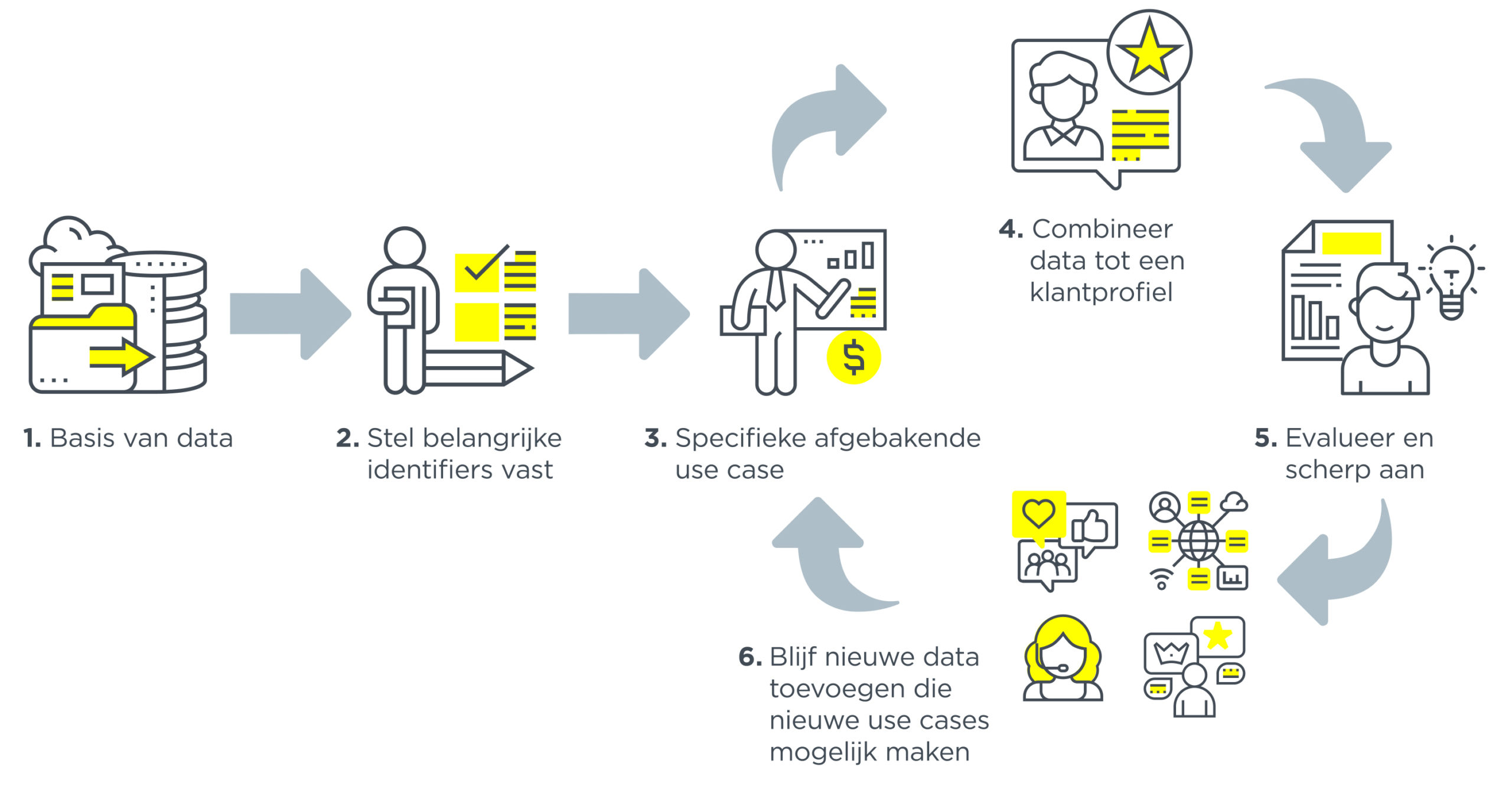
- Start met de basis; neem als uitgangspunt de beste versie van je huidige klantendatabase en zorg ervoor dat je deze in een werkbare en goed te ontsluiten omgeving zet.
- Identificeer vervolgens de belangrijke identifiers in de data als namen, klant- en telefoonnummers, e-mailadressen, etcetera.
- Stel vast welke klantinformatie nog meer nodig is om de bedrijfsdoelstellingen te realiseren. Maak dit concreet met het definiëren van een of enkele use-cases die bijdragen aan deze doelstellingen, inclusief waarde voor het bedrijf in bijvoorbeeld kostenbesparing, omzetverhoging, klanttevredenheid. Denk bijvoorbeeld aan een use case voor klantsegmentatie met een RFM-analyse waarbij je contactinformatie van klanten, orders, websitebezoek en campagnerespons combineert.
- Bepaal uit welke in- of externe bronnen je de benodigde data uit stap drie onttrekt. Verrijk de al beschikbare data van één en twee met data uit deze bronnen tot een eerste klantbeeld.
- Daarmee krijg je ervaring en lever je bewijs op van de effectiviteit van je use case(s).
- Vervolgens kun je het proces iteratief verder ontwikkelen door nieuwe data toe te voegen die nieuwe use cases mogelijk maken.
Deze pragmatische insteek is erg belangrijk. Veel bedrijven denken dat ze pas klaar zijn als ze een compleet 360 graden-beeld van de klant hebben. Je kunt echter met een klein deel van het klantbeeld ook al snel business-impact maken. Vaak is het toevoegen van één kolom aan klantdata al genoeg om de eerste use case uit te voeren. Daar komen we in het vijfde artikel van deze serie op terug.
Digital talk
Dit is het tweede artikel in de vijfdelige serie over het realiseren van een centraal klantbeeld, geschreven door de DDMA Commissie Data, Decisions & Engagement. In het volgende artikel gaan we in op de inrichting van de technologie-architectuur, gevolgd door twee artikelen over organisatie-inrichting en business impact. De commissie organiseert op 10 juni een Digital Talk over de inrichting van data en technologie voor een centraal klantbeeld.
Over de auteurs: Jan Hendrik Fleury is commercial director bij Crystalloids en Tjark Verhoeven is marketing technologist bij Louwman & Parqui,
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond