Google van de toekomst: SEO op basis van entiteiten
In ons laatste gesprek met een SEO-expert werd het al kort genoemd: Google zal in de toekomst meer en meer semantiek toevoegen aan de zoekmachine. Aan de hand van de context hoopt het bedrijf betere voorspellingen te kunnen doen.
Nog diezelfde week introduceerde het bedrijf op haar vijftiende verjaardag een update die wel eens de grootste verandering in jaren zou kunnen inhouden. De potentiële impact zou zo groot zijn dan geen marketeer zich het kan veroorloven om deze update te negeren.
De wijziging in Google’s algoritme, Hummingbird, is een belangrijke stap van het zoeken op basis van zoekwoorden naar begrijpen van entiteiten. De toekomst moet een zoekmachine opleveren die niet langer kijkt naar de absolute betekenis van een zoekwoord, maar de focus verlegt naar het eigenlijke doel van de zoekopdracht. De zoekmachine leeft zich in. Zowel in de zoekende entiteit als het beoogde resultaat. Resultaten moeten een direct antwoord vormen op de gestelde vraag en niet langer pagina’s tonen die overeenkomen met enkele zoekwoorden.
Woorden van betekenis
Langzaam maar zeker wordt het algoritme dusdanig aangepast, dat niet het presenteren van links het doel is, maar antwoord geven op je vragen. Een van de eerste zichtbare producties werd Knowdledge Graph. Daarin laat Google zien dat het een gigantisch overzicht bouwt van de bestaande elementen en hun onderlinge samenhang. Ook Google Now maakt er gebruik van. De dienst biedt content op basis van context en voert het handelingen uit binnen producten waarmee het in verbinding staat.
Structuur versus chaos
Het wereldwijde web is opgebouwd uit ongestructureerde, grote, hoeveelheden data. Data die niet georganiseerd of geclassificeerd is naar enig model. Zoekmachines zijn aan de hand van steekwoorden in staat patronen te herkennen binnen webpagina’s maar kenden eerder geen daadwerkelijke betekenis toe.
Met de introductie van het semantisch zoeken, wordt ieder stukje informatie als entiteit beschouwd en structuur aangebracht in de warboel. Een gemiddelde webpagina in een retailomgeving bevat bijvoorbeeld tientallen entiteiten: De prijs, kleur, grootte, status, merk, reviews enzovoorts. Door deze data te structureren krijgt de zoekmachine begrip van wat de pagina vertelt en kan het zeer accuraat de zoekresultaten verscherpen. Het begrijpt niet alleen wat de entiteit zelf ‘vertelt’, maar ook aan welke andere entiteiten deze gerelateerd is. De Knowledge Graph had vorig jaar al ruim vijfhonderd miljoen entiteiten in kaart gebracht en drieeëneenhalf miljard relaties waargenomen. Google kennende betreft dit inmiddels een veelvoud.
Het slimmere zoeken
Het slimmere zoeken levert in de praktijk rijkere resultaten op. Het moet de gebruikers gedetailleerde informatie bieden over een onderwerp. Met de uitrol van de nieuwste update is nauwkeurig filteren mogelijk en is het direct mogelijk zaken te vergelijken.
Zo wordt in onderstaand voorbeeld een poging gedaan een geschikt restaurant te vinden. De carrousel toont een grote hoeveelheid informatie en trekt direct de aandacht. De filter kan ingezet worden ter vergelijking en verfijning van de suggesties. Zo kan er geselecteerd worden op gemiddelde prijs en beoordeling.
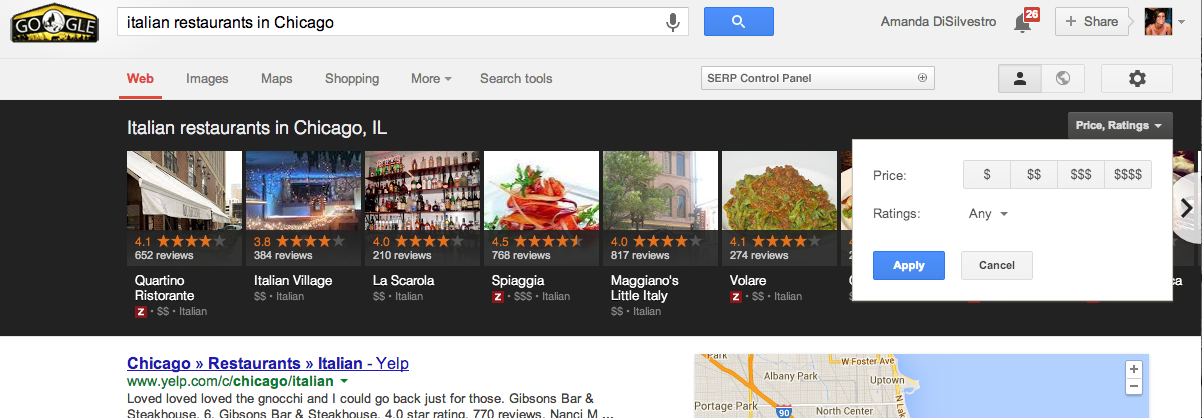
De antwoordenmachine die Google hoopt te worden wordt in eerste vorm al ingezet. Zo moet het uiteindelijk voor iedereen mogelijk worden een overzichtelijke vergelijking op te vragen. Op basis van entiteiten kunnen feiten worden gepresenteerd.
Zoekmachine-optimalisatie van vandaag de dag behelst niet langer het inrichten van websites zodat deze geïndexeerd kunnen worden. Websites moeten technisch worden voorzien van door machines leesbare kenmerken, zodat ze kunnen dienen als antwoord. Het in kaart brengen van de entiteiten maakt het voor de zoekmachine eenvoudiger zoekresultaten te personaliseren en te verrijken, met een hogere conversie als resultaat. De inzet van het intelligentere algoritme is slechts een eerste kleine stap. De echte verandering wordt nu langzaam zichtbaar.
Deel dit bericht
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond
1 Reactie
Wouter Blom
Yoshi,
ken je http://www.wolframalpha.com/ ? die gaat op basis van data al een heel stuk verder dan google. Daar kan je bijvoorbeeld aangeven dat je het bbp van de us wil delen door de leeftijd van de huidige president. Er wordt dan begrepen wat het bbp van de us is, en wie de president is en je krijgt daadwerkelijk een antwoord. (met de uitleg hoe hij er aan gekomen is.)
het nadeel van WA is dat alle data moet worden gestructureerd door de medewerkers en dat het (nog) niet het hele internet doorzoekt.