CRO: In vijf stappen naar een evidence-based prioriteringsmodel
Conversieoptimalisatie bestaat al een tijdje. In de loop der jaren hebben we ons verdiept in onderwerpen als statistiek, psychologie, server-side testen en automatisering. Een onderwerp waarvoor minder aandacht is, is prioritering. Hoog tijd om daar verandering in te brengen.
Natuurlijk zijn veel bedrijven overgestapt van een basisframework, zoals PIE en ICE, naar een completer framework, zoals PXL. De meeste bedrijven gebruiken dergelijke modellen al jaren. Tijd, dus, om het model te optimaliseren en te valideren om een grotere impact op de bedrijfsdoelen te realiseren.
In dit artikel stel ik een gedeeltelijk geautomatiseerd en evidence-based prioriteringsframework voor, met een dubbele feedbackloop om betere A/B-tests uit te voeren en meer winnaars te vinden.
PIE-, ICE- en PXL-frameworks: de nadelen
We gebruiken al heel lang PIE-, ICE- en PXL-gerelateerde frameworks. Niet alleen binnen conversieoptimalisatie, maar ook growth hackers gebruiken dergelijke modellen.
Het voordeel van deze modellen is hun eenvoud. Vooral modellen zoals PIE en ICE hebben slechts drie cijfers nodig om tot een prioriteitsscore te komen. PXL-gerelateerde frameworks hebben ongeveer tien getallen nodig, maar omdat dit model veel meer op feiten is gebaseerd, was het jarenlang mijn favoriete framework. Echter, al deze modellen hebben ook een paar grote nadelen.
- Allereerst zijn PIE en ICE volledig subjectief. We geven subjectieve scores aan elk attribuut. Neem bijvoorbeeld ‘potential’ binnen PIE of ‘confidence’ binnen ICE. Met een A/B-getest winstpercentage van, laten we zeggen, 25%, hoe zeker kun je dan zijn? Hoe zeker ben je van het potentieel?
- Ten tweede is er te veel aandacht voor gemak. Binnen PIE en ICE draagt ‘gemak’ 33,3% bij aan de totaalscore! Dat gaat ten kosten van innovatieve experimenten. Als iets moeilijk te bouwen is, belandt het onderaan de backlog. Bij PXL heeft ‘gemak’ minder impact op de totaalscore. Het is echter nog steeds het attribuut dat van alle tien attributen de hoogste score kan halen. Het gemak is natuurlijk belangrijk om een hoge testsnelheid te realiseren. Complexe experimenten, zoals nieuwe functionaliteiten, kunnen echter een grotere impact hebben. Een combinatie van beide is essentieel.
- Ten derde is er weinig tot geen afstemming met de bedrijfsdoelstellingen. Ik neem aan dat wanneer je experimenten uitvoert, het hoofddoel hetzelfde zal zijn als het doel van het bedrijf. Toch helpt het om af te stemmen op de huidige bedrijfs OKR’s (Objectives en Key Results) of OGSM’s (Objective, Goals, Strategies en Measures) om relevante experimenten uit te voeren. Dit helpt bij de acceptatie van experimenteren in de gehele organisatie.
- En ten vierde, en misschien wel het belangrijkste voor PXL-gerelateerde frameworks: er is een enorm gebrek aan bewijs en feedback. Bijvoorbeeld: in het PXL-model krijgen ideeën met betrekking tot problemen die worden gevonden in kwalitatieve feedback een hogere score. Echter, dit leidt niet per se tot betere experimenten. Misschien hebben ideeën met betrekking tot kwalitatieve feedback in jouw situatie wel een laag winnaarspercentage. Toch geef je deze ideeën consequent een hogere score, waardoor je winstpercentage voor experimenten aanzienlijk daalt! Een ander voorbeeld zijn ideeën die te maken hebben met motivatie. In het PXL-model geef je deze ideeën een hogere score, maar misschien leiden experimenten met betrekking tot ability tot veel meer winnaars.
Vijf stappen voor een nieuw prioriteringsmodel
We hebben daarom een prioriteringsmodel nodig dat ons helpt betere beslissingen te nemen, zodat we betere A/B-tests kunnen uitvoeren en betere inzichten kunnen krijgen. Tegelijkertijd willen we de eenvoud van de huidige modellen behouden. Het model moet ook evidence-based zijn, tot op zekere hoogte geautomatiseerd, en met een (dubbele) feedbackloop op basis van het succes van afgeronde experimenten.
1. Documenteer de psychologische richting voor elk experiment
De ervaring leert dat wanneer je psychologie op de juiste manier inzet in je experimenteerprogramma, je winstpercentage zal stijgen. De eerste stap is daarom het documenteren van de psychologische richting voor elk experiment. Hiervoor kun je het psychologische model gebruiken dat je voorkeur heeft. Ik benoem er twee:
- Het meest eenvoudige model is het Fogg-gedragsmodel. Documenteer voor elk experiment of je de motivatie of de ability probeert te vergroten of een prompt toepast.
- We werken zelf met onze eigen Behavioural Online Optimization Method (BOOM).
2. Bereken het winstpercentage en de impact van elke richting voor elke pagina
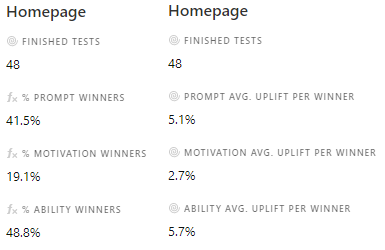
Voorbeeld uit Airtable.
Nadat je de psychologische richting hebt gedocumenteerd kun je het winstpercentage en de impact (gemiddelde conversiestijging per winnaar voor je belangrijkste KPI) voor elke psychologische richting op elke pagina berekenen.
Bij Online Dialogue gebruiken we Airtable als documentatie-tool. In deze tool is het eenvoudig om deze berekeningen te maken. En aangezien we alles in Airtable documenteren, inclusief experiment resultaten, kost het automatiseren van prioriteringsscores geen moeite (zie volgende stap). Uiteraard kun je ook een andere tool gebruiken.
3. Gebruik de scores als start en automatiseer (eerste feedbackloop)
De volgende stap is het opzetten van je prioriteringsmodel. Het begin van je model is de score van de vorige stap. Voor het winstpercentage kun je het getal door 10 delen. Een winstpercentage van 41,5% wordt dus 4,15 punten. Voor de impact kun je de scores een-op-een overnemen. Een gemiddelde stijging per winnaar van 5,1% wordt dus een score van 5,1. Op basis van de bij punt 2 gegeven afbeelding krijgt elk experimentidee op je backlog dat een prompt toepast op de home page een score van 4,15 + 5,1 = 9,25.
Natuurlijk moeten deze scores automatisch worden bijgewerkt. Na elk experiment verandert het winstpercentage en na elk winnend experiment kan de impact veranderen. Je documentatie-tool zou deze berekeningen automatisch moeten doorvoeren, waardoor prioriteringsscore van de ideeën op je backlog ook automatisch bijgewerkt worden. Met Airtable is dit relatief eenvoudig te doen.
4. Voeg andere kenmerken toe die van toepassing zijn
Vervolgens wil je misschien extra attributen toevoegen die van toepassing zijn op jouw bedrijf. Bijvoorbeeld:
- Afstemming met bedrijfsdoelen en OKR’s – belangrijke testdoelen krijgen een hogere score
- Percentage verkeer dat de verandering zal zien – boven de vouw krijgt een hogere score
- Minimal detectable effect – lager MDE krijgt een hogere score
- Percentage van de omzet dat door de pagina gaat – hoger percentage krijgt een hogere score
- Urgentie – urgenter betekent een hogere score
- Gemak – zorg ervoor dat je eenvoudige en complexe tests voor snelheid en impact in evenwicht houdt
Drie dingen om daarbij in gedachten te houden:
- Zorg er eerst voor dat het winnaarspercentage en de impact het hoogste gewicht hebben in de totale prioriteitsscore. Deze zijn gebaseerd op eerdere experimenten en zouden de beste voorspeller moeten zijn voor je volgende experiment.
- Voeg niet te veel attributen toe: dit vertraagt het prioriteringsproces.
- Scoor deze extra attributen zoals jij denkt dat goed is voor je experimentenprogramma en optimaliseer in stap 5.
5. Valideer en optimaliseer (tweede feedbackloop)
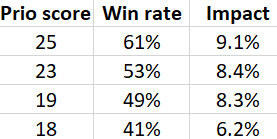
Voorbeeld van een draaitabel.
Marketeers zijn optimaliseerders! We analyseren data en optimaliseren: waarom doen we dit dan niet voor ons prioriteringsmodel? Met de juiste documentation tool, of met een exportfunctie, kun je een draaitabel maken. Toon op de verticale as de prioriteitsscores (of een reeksscores) van alle voltooide experimenten. Geef op de horizontale as het winstpercentage en de gemiddelde impact van deze experimenten weer.
De experimenten met de hoogste prioriteitsscore zouden het hoogste winstpercentage en de hoogste impact moeten hebben. Is dat niet het geval, pas dan je model aan. Wijzig bijvoorbeeld de score van de extra attributen of geef meer gewicht aan de winnaars- en impactscores. Blijf experimenteren en blijf je model optimaliseren.
Betere prioritering voor betere beslissingen
Een succesvol experimentenprogramma zorgt ervoor dat er binnen je organisatie enthousiasme komt en blijft voor experimenteren en valideren. Het succes van je programma wordt vaak bepaald door het aantal A/B-testwinnaars en waardevolle inzichten uit je experimenten. Om de beste experimenten uit te voeren is een goed prioriteringskader essentieel.
Prioriteringsmodellen moeten eenvoudig, evidence-based en tot op zekere hoogte geautomatiseerd zijn, en moeten een (dubbele) feedbackloop hebben op basis van het succes van eerdere experimenten. Er is, naar mijn idee, te weinig aandacht voor het belang van prioritering. Hopelijk gaan meer organisaties het belang van een evidence-based model inzien en vervolgens ook gebruiken – afgestemd op de eigen bedrijfsdoelen – om nog succesvoller te worden met experimenteren.
Over de auteur: Ruben de Boer is Conversiemanager bij Online Dialogue.
Op de hoogte blijven van het laatste nieuws binnen je vakgebied? Volg Emerce dan ook op social: LinkedIn, Twitter en F
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond