Gebruik een data driven attributiemodel, eenvoudige werken niet
Met de komst van nieuwe onlineplatformen wordt de customer journey steeds complexer. Het is inmiddels heel gewoon dat een customer journey een aantal touchpoints op verschillende platformen omvat voorafgaand aan een conversie. De uitdaging bij deze langdurige customer journeys is het bepalen hoeveel elk kanaal heeft bijgedragen aan die conversie.
Eenvoudige attributiemodellen werken niet
Meestal worden eenvoudige attributiemodellen gebruikt om inzicht te krijgen in hoe een kanaal presteert, maar dergelijke modellen zijn enorm willekeurig. Voorbeelden hiervan zijn de modellen Linear, Last-click, Last-AdWords click en First-click (zie afbeelding).
Deze modellen geven een vertekend beeld van de kanaalprestaties omdat ze primair zijn gebaseerd op aannamen, kennis van de business en een onderbuikgevoel. De kans dat kanalen worden over- of ondergewaardeerd is heel groot, terwijl dat nu juist moet worden vermeden om campagnebudgetten op effectieve en efficiënte wijze toe te kunnen wijzen.
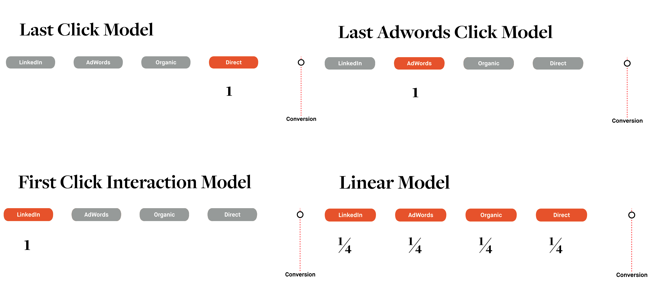
Voorbeelden van eenvoudige attributiemodellen
In plaats hiervan moeten we een data driven attributiemodel hanteren
Dit vertekende beeld kan worden vermeden door een combinatie te gebruiken van businesskennis en data om een data driven attributiemodel te maken. Zo’n model omvat alle mogelijke combinaties van kanalen in een customer journey en evalueert de conversieratio daarvan op basis van historische data. Die informatie wordt gebruikt om algoritmisch te berekenen wat de toegevoegde waarde is van een specifiek kanaal op een specifiek punt in de customer journey.
Een veelgebruikt algoritme voor dit soort berekeningen is de Shapley-waarde uit de coöperatieve speltheorie. Ik ga daar nu niet verder op in, omdat die hier al uitgebreid wordt beschreven, en ook Google geeft een wat algemenere uitleg hier.
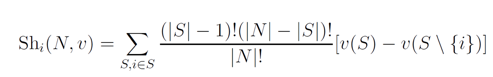
Shapley-waarde
De beperkingen van Google
Het is dus niet verrassend dat Google een data driven attributiemodel ter beschikking stelt voor hun Google 360 Suite. En hoewel dit een enorme verbetering is met betrekking tot het correct toeschrijven van kanalen met Google Analytics, heeft het door Google gehanteerde model een aantal belangrijke beperkingen. Hieronder ga ik kort in op de voornaamste daarvan:
- Alleen standaardkanaalgroepering
- Maximumlengte van customer journey
- Vooraf bepaalde businessregels
- Geen omni-channel attributie
1. Alleen standaardgroepering van kanalen
Ten eerste kan Googles data driven attributiemodel alleen waarden berekenen voor kanalen die volgens de standaardmethode zijn gegroepeerd (link). Dit betekent dat als je zowel een samengevoegd als gedetailleerd beeld wilt van de prestaties van jouw kanalen, je de standaardkanaalgroepering moet aanpassen in een aparte weergave om een ander perspectief te krijgen. Dit lost de beperking wel op, maar is behoorlijk foutgevoelig en bepaald niet gebruiksvriendelijk.
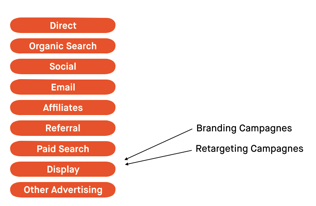
Voorbeeld van standaardkanaalgroepering
2. Maximumlengte van customer journey
Ten tweede werkt het model alleen met customer journeys die uit maximaal vier touchpoints bestaan (link), wat betekent dat een customer journey met meer punten wordt teruggebracht tot de laatste vier (zie de volgende afbeelding). Dit is een ernstige beperking voor bedrijven die producten verkopen waarvoor meestal meer dan vier interacties nodig zijn, door bijvoorbeeld een langdurige oriëntatiefase.

Maximumlengte van customer journey
3. Vooraf bepaalde businessregels
Ten derde zijn de businessregels die door Google op de data worden toegepast onbekend, en kunnen ze dus niet worden aangepast voor specifieke bedrijfs- of sectorkenmerken. De definitie van een customer journey is essentieel voor het data driven attributiemodel, omdat het algoritme de individuele customer journeys gebruikt om te attribueren. Zo kan een touchpoint kort na een aankoop worden gezien als deel van de loyalty loop van de vorige customer journey (link) in plaats van als het begin van een nieuwe customer journey van die klant.
Bovendien is het in sommige sectoren heel gewoon dat een klant meerdere keren de website bezoekt, voordat zijn vertrouwen is gewonnen en de eerste aankoop wordt gedaan. Maar zodra dit omslagpunt is bereikt, resulteert elk volgend bezoek in een aankoop. Deze aankopen zouden ook moeten kunnen worden toegeschreven aan de kanalen in het oriëntatieproces. Kortom, de meeste bedrijven en sectoren moeten hun customer journey zorgvuldig definiëren om een data driven attributiemodel effectief en efficiënt te gebruiken en de prestaties van hun kanalen op de juiste manier te bepalen.
4. Geen omni-channel attributie
Ten slotte is de belangrijkste beperking van Googles data driven attributiemodel dat er geen omni-channel attributie mogelijk is, omdat de customer journey is samengesteld met de gegevens uit de producten van Google. Het is dus wenselijk dat er touchpoints afkomstig uit andere bronnen dan die van Google (CRM, e-mail, winkel enzovoort) worden opgenomen in de customer journey, voordat het attributiemodel wordt gebruikt. Helaas is het model van Google niet geschikt voor externe databronnen, en kan het dus niet worden toegepast op rijkere datasets, die een completer beeld bieden van de omni-channel touchpoints in de customer journey.
De oplossing is een aangepast data driven attributiemodel
Naar aanleiding van de bovenstaande beperkingen van het model van Google besloot ik om zelf een data driven attributiemodel te ontwikkelen, dat deze beperkingen niet heeft en ook kan worden gebruikt met een basisaccount van Google Analytics.
In mijn attributiemodel heb ik ook de Shapley-waarde uit de coöperatieve speltheorie gebruikt. Het model is ontwikkeld met de open-sourcesoftware R (link). Met een combinatie van de flexibiliteit van R, ruim 1000 regels handgeschreven code en de ruwe data van het bedrijf, is het mogelijk om een eigen data driven attributiemodel te maken, dat kan worden aangepast en afgestemd op de behoefte van een bedrijf. In dit gedeelte leg ik kort uit hoe ik met dit model de beperkingen vermijd van Google’s data driven attributiemodel.
- Ondersteuning van aangepaste kanaalgroepering
- Ondersteuning van lange customer journeys
- Ondersteuning van aangepaste businessregels
- Omni-channel attributie is mogelijk
1. Ondersteuning van aangepaste kanaalgroepering
Het eerste grote voordeel is de mogelijkheid om meerdere sets kanaalgroeperingen te definiëren, waarmee de prestaties van een kanaal algoritmisch kunnen worden berekend. Met andere woorden, deze flexibiliteit biedt de mogelijkheid om eenvoudig in te zoomen op specifieke kanaalgroeperingen en de prestaties in detail te bekijken.
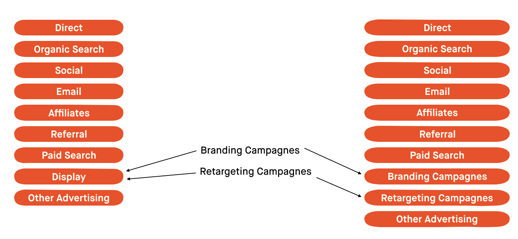
Ondersteuning van aangepaste kanaalgroepering
2. Ondersteuning van lange customer journeys
Het tweede grote voordeel is de mogelijkheid om de lengte van de customer journey aan te passen waarover het attributiemodel de kanaalprestaties berekent. Bedrijven die producten verkopen met een vaak lange customer journey kunnen dit aangepaste attributiemodel dus gebruiken zonder dat ze essentiële upper-funnel touchpoints hoeven uit te sluiten.

Ondersteuning van lange customer journeys
3. Aangepaste businessregels
Verder is een van de grootste beperkingen van Googles model dat alle businessregels over de customer journey vooraf zijn gedefinieerd en niet kunnen worden aangepast. Deze kunnen enorme gevolgen hebben voor de uitkomsten van het model, en kunnen en mogen dus niet worden gestandaardiseerd.
Dit is ook de reden dat mijn aangepaste data driven attributiemodel werkt met de ruwe data, zodat de gebruiker de businessregels die van toepassing zijn op de klant helder kan definiëren. Dit betekent dat er businessregels en sectorspecifieke regels kunnen worden gebruikt voor de customer journeys.
Daarnaast maakt dit het attributiemodel niet alleen bruikbaar voor alle bedrijven in verschillende sectoren, maar wordt het proces ook volledig transparant doordat alle details over hoe de toeschrijving wordt uitgevoerd, beschikbaar zijn en tot in detail kunnen worden verklaard.
4. Omni-channel attributie is mogelijk
Het aangepaste data driven attributiemodel is niet afhankelijk van de Google-omgeving en kan worden gebruikt met externe databronnen (CRM, e-mail, winkel enzovoort), waardoor omni-channel attributie mogelijk is. Met andere woorden, wanneer je een Data Management Platform (DMP) gebruikt dat gebruikers-ID’s van verschillende databronnen aan elkaar koppelt, kan het aangepaste attributiemodel worden gebruikt om algoritmisch de omni-channel prestaties te berekenen.
Maar er is nog meer
Behalve dat ik de beperkingen van het attributiemodel van Google wilde wegnemen, was ik ervan overtuigd dat er meer winst te behalen viel. Daarom heb ik een aantal extensies ontwikkeld die de output van het data driven attributie model nog waardevoller maakt. Ik denk dan aan mogelijkheden zoals een analysetool voor ‘Return on Ad Spend” (ROAS) en “Channel weight dashboard”.
De eerste tool geeft inzicht in het rendement van de uitgaven aan advertenties in elke aangepaste kanaalgroepering, op basis van de attributiewaarde en het budget dat in het kanaal is gestoken. Hierdoor kan beter worden bepaald hoeveel omzet elk kanaal genereert in verhouding tot de investering. Het dashboard biedt waardevolle inzichten in de prestaties van elk kanaal voor elke stap in de customer journey. Dit kan worden gebruikt om te bepalen in welke fase van de customer journey een kanaal het beste presteert. Het ligt voor de hand dat sommige kanalen beter zijn voor het vergaren van prospects, en sommige effectiever zijn bij het genereren van conversies.
Conclusie
Data driven attributie is een onwillekeurige, goede methode voor het vaststellen van de prestaties van een kanaal, en zou moeten worden gebruikt door alle bedrijven die willen weten wat het effect en de resultaten zijn van hun marketingbudgetten. Door het gebruik van de ruwe data kunnen we het attributiemodel volledig personaliseren voor elke business door middel van aangepaste businessregels, de lengte van de customer journey en de kanaalgroepering.
Daarnaast is het essentieel dat data driven attributiemodellen flexibel zijn en kunnen worden gebruikt met uiteenlopende databronnen. Dit is vooral belangrijk omdat customer journeys steeds complexer worden en de grens tussen offline en online vervaagt. Dat vraagt om een omni-channel benadering. We moeten dus allemaal onze huidige attributiemodellen inwisselen voor een data driven attributiemodel, zodat we onze kanalen niet over- of onderwaarderen.
Deel dit bericht
Plaats een reactie
Uw e-mailadres wordt niet op de site getoond
10 Reacties
Sander - Brandfield
Beste Job,
Super interessant artikel.
In de conclusie schrijf je dat we ‘allemaal’ data driven attributie moeten gebruiken.
In mijn ervaring heb je een beste bak data (conversies) nodig om via de Shapley-waarde uit de coöperatieve speltheorie een conversie over de juiste touchtpoint te attribueren. Nederland is hier vaak te klein voor. Hoe denk jij hierover?
Daarnaast ben ik wel heel benieuwd wat je nou uiteindelijk gebouwd hebt en hoe je/jullie dit gebruikt. Je claimt een beter beter data driven atributiemodel dan die van GA(360) te hebben geschreven.
Laatste punt is dat, na mening, de kracht van attributie ligt in het actionable maken van de data.
Een first click en/of lineair model kunnen dit om dat ze juist simpel te begrijpen, te intrepeteren zijn en daardoor makkelijk omgezet kunnen worden in actie. Ook al geven deze modellen alles behalve de waarheid weer.
Groet,
Sander
Sjoerd
Wat een enorme bak blabla Eens met Sander dat je enorm veel data, dus conversies, nodig hebt om op een dergelijke manier te kunnen werken en in NL bijna niet te realiseren valt. Theorie is leuk en klinkt interessant maar de praktijk ziet er echt heel anders uit.
Egbert van Keulen
@Sjoerd,
Dank voor je reactie. Kun je svp uitweiden over hoe de praktijk er op dit gebied dan volgens jou uit ziet. Benieuwd naar je inzichten.
Egbert
Job Deibel - Expand Online (Dept)
Beste Sander,
Bedankt voor je reactie en je goede vragen.
De hoeveelheid data die nodig is om een data driven attributiemodel te gebruiken is zeker niet onbereikbaar. Net zoals Google (https://support.google.com/analytics/answer/3264076?hl=en&ref_topic=3180362&rd=1) maak ik gebruik van de threshold van 10000 customer journey’s en 400 conversies aan data die nodig zijn om de attributie te kunnen doen. Dit is voor de meeste websites/apps met een beetje verkeer geen probleem. In andere woorden, de hoeveelheid data is zeker geen probleem mits het aantal kanaalgroeperingen waarover je attribueert aanzienlijk groter is dan het standaard aantal groeperingen (>10).
Het data driven attributiemodel dat ik gebouwd heb is een “stand-alone” product dat conversies attribueert (gebaseerd op patronen in de data – Shapley) over de touchpoints van de customer journeys. Omdat het een “stand-alone” product is en niet afhankelijk van een specifieke infrastructuur kan het worden gebruikt met verschillende databronnen, bijvoorbeeld een DMP, CRM, of ATS (deze moeten dan uiteraard wel een data-integratie hebben met de website). Daarnaast is het customizen van de customer journeys en kanaalgroeperingen mogelijk omdat het met de ruwe data werkt wat het model erg flexibel inzetbaar maakt.
De output van het model is het aantal conversies per kanaalgroepering dat vervolgens wordt gebruikt om campagnebudgetten beter in te zetten. Er zijn ook uitbreidingen op deze standaard output die interessante actionable-insights geven (zie kopje “Maar er is nog meer”). Ik ben het met je eens dat de interpretatie van hoe de attributie van dit model tot stand komt wat minder makkelijk te begrijpen is, maar geeft daarentegen een beter beeld van de werkelijkheid. In mijn mening is het doel van een attributiemodel het bepalen van hoe goed elk kanaal presteert en niet zozeer hoe vaak een kanaal het laatste kanaal was in een converterende customer journey (last-click attributiemodel). Alhoewel dit ook interessante inzichten geeft staat dit in mijn mening los van de gegenereerde waarde van het kanaal en moet je hier niet je campagnebudgetten op baseren.
Ik hoop dat ik je vragen goed heb kunnen beantwoorden.
Groet,
Job
Stefan
Het belangrijkste onderwerp is voor mij hoe je offline Sales verwerkt in het contributiemodel. Hier lees ik alleen dat het te koppelen valt. Wat ik graag zou willen weten is hoe je het meest realistisch transacties in de winkel kunt toekennen aan de online journey. Oftewel, hoe zorg je ervoor dat er zonder natte vingerwerk transacties die in de winkel plaatsvinden terug te herleiden zijn aan je online activiteiten. Door alleen naar productpage views te kijken en deze te koppelen aan offline sales is niet nauwkeurig bijvoorbeeld. Ik zou hier graag wat goede cases over lezen.
Sander
Dank Job
Peter W
Job, welke R librarys heb je gebruikt voor je handgeschreven attributiemodel?
Job Deibel - Expandonline
Ha Peter, Ik maak alleen gebruik van de data.table, gtools library en gewoon base-R. Omdat er geen bruikbare Shapley libraries zijn voor dit soort attributie heb ik de functies, loops en logica zelf geschreven.
Peter W
Aha interesting, ik heb zelf ook met dit probleem geworsteld en gekeken naar de Shapley methode. Ben erg benieuwd hoe jij hier invulling aan hebt gegeven. Ik ben hier uiteindelijk niet mee verder gegaan. Dit omdat resultaten toch vaak First Click georiënteerd waren. Ben je ook bekend met de Markov methode? Deze bood voor mij meer uitkomst.
Job Deibel - Expandonline
Daar ben ik bekend mee maar omdat deze methode geen houdt rekening met de volgorde van de kanalen heeft deze niet mijn voorkeur. Dank voor je interessen